HashMap
先贴一张从网上偷来的图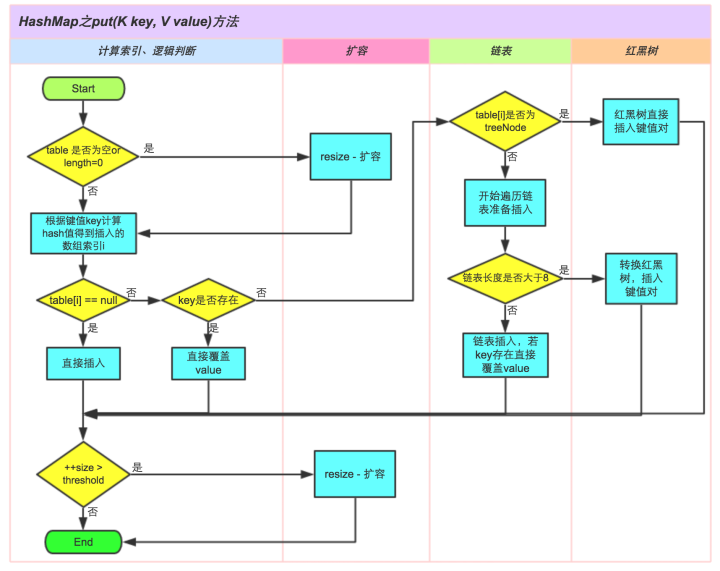
HashMap核心数据结构
Hash表 = 数组 + 线性链表 + 红黑树
为什么初始容量是2的指数幂?
如果创建HashMap时指定的大小不是2的指数就会报错吗?
Map map = new HashMap<>(13);这行代码在编译的时候也不会报错,那为什么说初始容量是2的指数呢?
看一下HashMap的构造器
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 调用了tableSizeFor()方法
this.threshold = tableSizeFor(initialCapacity);
}
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}tableSizeFor写的奇奇怪怪的嘞, 这一长串是干嘛呢?
因为initCapacity必定大于等于0, 所以在他的二进制数中,首位必然是1.而且initCapacity最大值又小于32位.
因此,先将他右移一位取或,结果的前两位必然也是1,依次将后续的所有位数全部变成1, 得到的就是他所在的,距离值最近的2^n-1. 最后将该值 +1 就得到了比initCapacity大,且距离最近的2的指数值.
那为什么呢? 为什么一定要将容量设置为2的指数呢?初始容量给多少就是多少不行吗?
先提一些题外话, 哈希值可以很大也可以很小,如何将这个很大范围的哈希值塞进很小的一个数组里呢?
很容易想到的方法就是对这个值取余,这样不管多大的数值,散布在这个数组各个索引的概率也差不多相等.
在HashMap中,计算索引的方法是
// n = table.length
// hash = hash(key)
i = (n - 1) & hash
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}因为n都被置为2的指数,n = 0000 0000 0100 0000, n - 1 = 0000 0000 0011 1111,这样做且运算时,hash值前面的位数和0做&计算都是0,直接取hash后几位就可以了,而且这个结果的范围就在0 ~ n-1之间.
加载因子为什么是0.75?
/*
* <p>As a general rule, the default load factor (.75) offers a good
* tradeoff between time and space costs. Higher values decrease the
* space overhead but increase the lookup cost (reflected in most of
* the operations of the <tt>HashMap</tt> class, including
* <tt>get</tt> and <tt>put</tt>). The expected number of entries in
* the map and its load factor should be taken into account when
* setting its initial capacity, so as to minimize the number of
* rehash operations. If the initial capacity is greater than the
* maximum number of entries divided by the load factor, no rehash
* operations will ever occur.
*/从HashMap中摘下来的一段注释, 加载因子决定了当数组填充多少时,才开始扩容.
理论上来说数组的每个位置都是有均等的可能放入元素的,那是不是填个1,当所有的位置都占满了才去扩容呢?
理论是这样的,但是会有可能发生 有一个位置就是没有数据,其他格子下链的数据已经堆积起来了. 这样去get(key)的时候会花费更长的时间.
同样的道理,基于空间上考虑,在尽量数组装的差不多的时候才去考虑扩容.毕竟每个位置放入元素的机会都是均等的.
因此,the default load factor (.75) offers a good tradeoff between time and space costs.
为什么链表长度为8的时候,会去转为红黑树?
这里要引入一个泊松分布的概念
泊松分布和指数分布:10分钟教程
在HashMap的源码中也有相应的概率显示
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million可以看到,在链表长度为8的时候概率已经非常小了, 已经小于千万分之一.所以即使在长度超过8的情况下链表会转成红黑树,树的出现依然很少见.Because TreeNodes are about twice the size of regular nodes.
JAVA7的HashMap扩容出现的问题
JAVA7中扩容的代码主要是下面这段. 当然,中间还有一段重新计算索引的被我删掉, 考虑的是扩容后链表内存放的数据重新计算数组下标依然一样的情况.
for (Entry<K, V> e : table){
while (null != e){
Entry<K, V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}如果进行扩容,扩容后的结果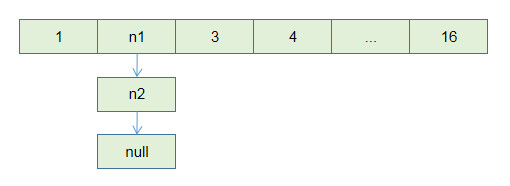
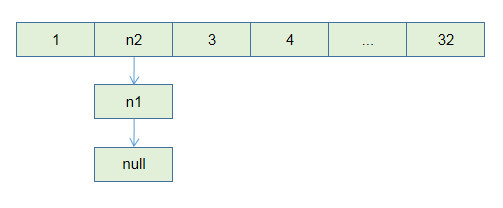
可以看到,扩容后链表是顺序倒了过来.
如果是两个线程同时遇到扩容问题,
t1为线程1, e1,next1为t1中的e和next对象.
t2为线程2, e2,next2为t2中的e和next对象.
若t2在Entry<K, V> next = e.next;时挂起,由t1执行,t1执行结束后: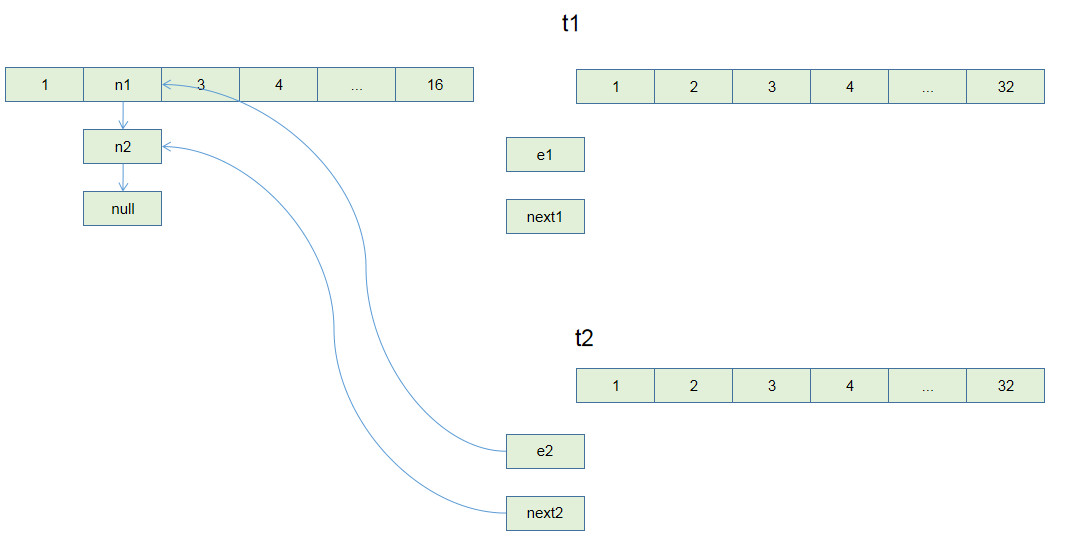
根据我们上面看到的扩容后链表顺序返过来,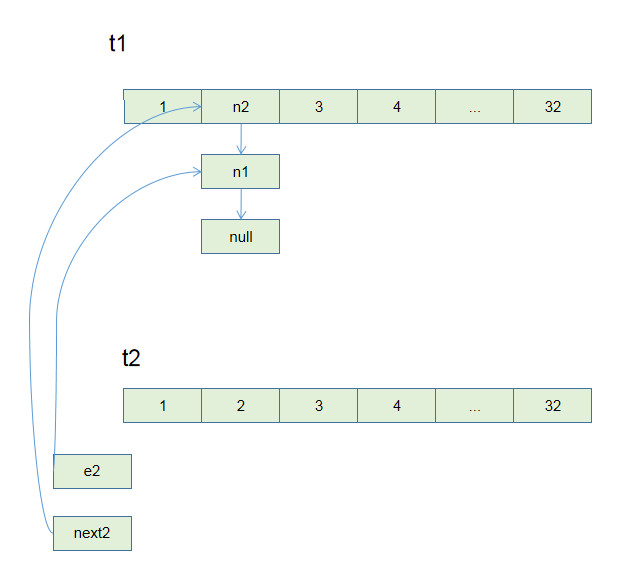
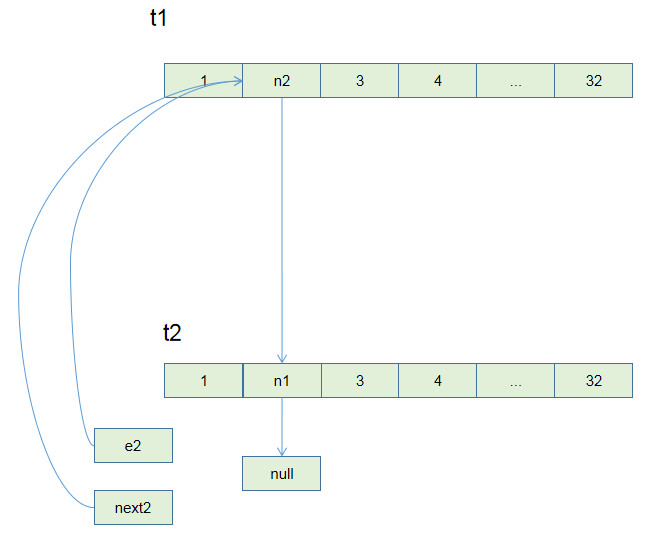
第二次循环执行完毕, 在t1时,两次循环后就已经跳出循环. 但是在t2这里, e仍然非空,所以要继续执行.
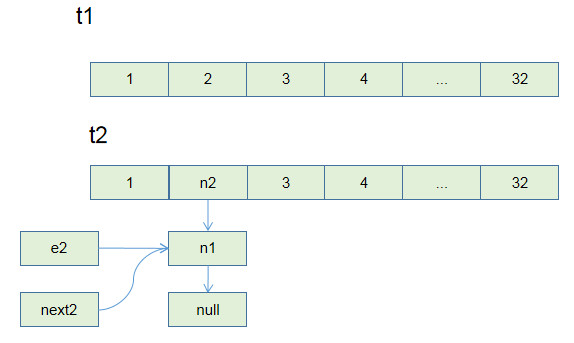
第三次循环执行到e.next = newTable[i];时,出现了一个问题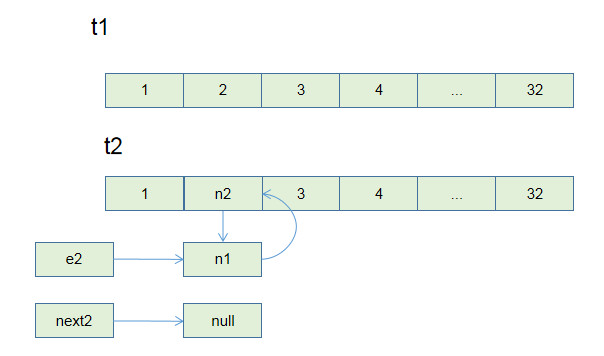
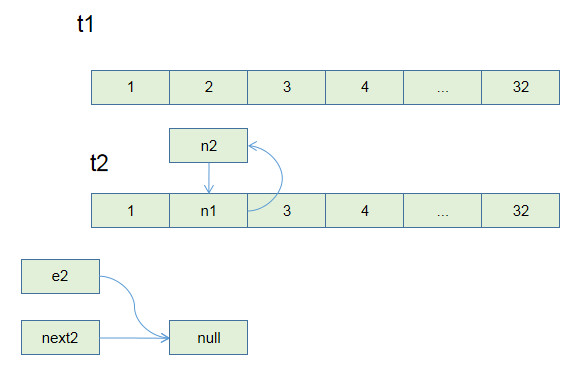
第三次循环结束时,e == null 结束循环.
但是t2线程中的链表已经形成了一个环状.
JAVA8的HashMap扩容
JAVA8中,HashMap的扩容不再使用重新计算数组下标,挨个移动. 这样就避免了next的指来指去导致链表形成环状的情况.
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}在JAVA8中, 使用的是四个指针,高低位指针,将链表直接分成两段. 低位将低位链表放入新数组的原索引位置, 高位将高位链表放入扩容出的新空间中,相应位置.
这样处理避免了挨个元素移动,并且将链表的长度减少.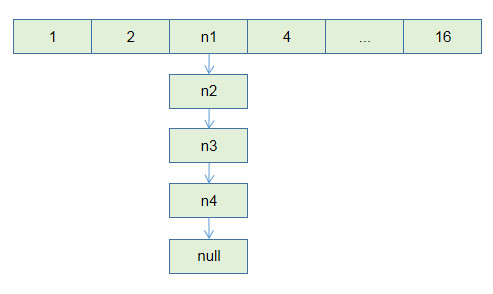
假设有这么一个数组, n1,n3计算结果为低位, n2,n4计算结果为高位.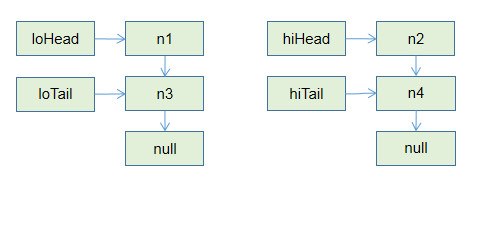
将loHead放到原来的3位置,hiHead放入3+16位置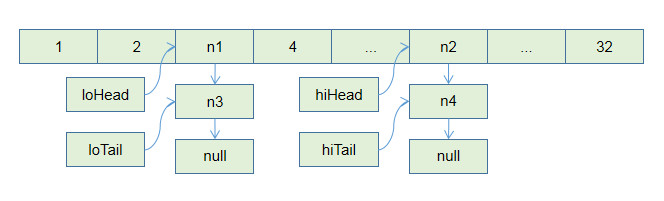
这样就避免了环状的情况,因为hash值和容量做计算的时候,结果始终是一样的.




