整体认识J.U.C, 之前也写过AQS相关的博客, 那时候听了一节课就匆匆忙忙的记笔记写博客, 对J.U.C也没有一个系统的学习.
最近翻到一篇博客写的挺全的,想拿来学习一下.
整体认识
首先要对J.U.C包下的内容做一个整体的认识.
- 原子操作
- 锁
- 并发容器
- 线程池
原子操作
“原子操作(atomic operation)是不需要synchronized”,这是多线程编程的老生常谈了。所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。
通常情况下,在Java里面,++i或者–i不是线程安全的,这里面有三个独立的操作:或者变量当前值,为该值+1/-1,然后写回新的值。在没有额外资源可以利用的情况下,只能使用加锁才能保证读-改-写这三个操作时“原子性”的。
基本数据类型的原子操作
int addAndGet(int delta)
以原子方式将给定值与当前值相加。 实际上就是等于线程安全版本的i =i+delta操作。
boolean compareAndSet(int expect, int update)
如果当前值 == 预期值,则以原子方式将该值设置为给定的更新值。 如果成功就返回true,否则返回false,并且不修改原值。
int decrementAndGet()
以原子方式将当前值减 1。 相当于线程安全版本的–i操作。
int get()
获取当前值。
int getAndAdd(int delta)
以原子方式将给定值与当前值相加。 相当于线程安全版本的t=i;i+=delta;return t;操作。
int getAndDecrement()
以原子方式将当前值减 1。 相当于线程安全版本的i–操作。
int getAndIncrement()
以原子方式将当前值加 1。 相当于线程安全版本的i++操作。
int getAndSet(int newValue)
以原子方式设置为给定值,并返回旧值。 相当于线程安全版本的t=i;i=newValue;return t;操作。
int incrementAndGet()
以原子方式将当前值加 1。 相当于线程安全版本的++i操作。
void lazySet(int newValue)
最后设置为给定值。 延时设置变量值,这个等价于set()方法,但是由于字段是volatile类型的,因此次字段的修改会比普通字段(非volatile字段)有稍微的性能延时(尽管可以忽略),所以如果不是想立即读取设置的新值,允许在“后台”修改值,那么此方法就很有用。如果还是难以理解,这里就类似于启动一个后台线程如执行修改新值的任务,原线程就不等待修改结果立即返回(这种解释其实是不正确的,但是可以这么理解)。
void set(int newValue)
设置为给定值。 直接修改原始值,也就是i=newValue操作。
boolean weakCompareAndSet(int expect, int update)
如果当前值 == 预期值,则以原子方式将该设置为给定的更新值。JSR规范中说:以原子方式读取和有条件地写入变量但不 创建任何 happen-before 排序,因此不提供与除 weakCompareAndSet 目标外任何变量以前或后续读取或写入操作有关的任何保证。大意就是说调用weakCompareAndSet时并不能保证不存在happen-before的发生(也就是可能存在指令重排序导致此操作失败)。但是从Java源码来看,其实此方法并没有实现JSR规范的要求,最后效果和compareAndSet是等效的,都调用了unsafe.compareAndSwapInt()完成操作。
下面的代码是一个测试样例,为了省事就写在一个方法里面来了。
public class AtomicIntegerTest {
@Test
public void testAll() throws InterruptedException{
final AtomicInteger value = new AtomicInteger(10);
assertEquals(value.compareAndSet(1, 2), false);
assertEquals(value.get(), 10);
assertTrue(value.compareAndSet(10, 3));
assertEquals(value.get(), 3);
value.set(0);
//
assertEquals(value.incrementAndGet(), 1);
assertEquals(value.getAndAdd(2),1);
assertEquals(value.getAndSet(5),3);
assertEquals(value.get(),5);
//
final int threadSize = 10;
Thread[] ts = new Thread[threadSize];
for (int i = 0; i < threadSize; i++) {
ts[i] = new Thread() {
public void run() {
value.incrementAndGet();
}
};
}
//
for(Thread t:ts) {
t.start();
}
for(Thread t:ts) {
t.join();
}
//
assertEquals(value.get(), 5+threadSize);
}
}AtomicInteger和AtomicLong、AtomicBoolean、AtomicReference差不多,这里就不介绍了。
数组的原子操作
在这一部分开始讨论数组原子操作和一些其他的原子操作
AtomicIntegerArray/AtomicLongArray/AtomicReferenceArray的API类似,选择有代表性的AtomicIntegerArray来描述这些问题。
int get(int i)
获取位置 i 的当前值。很显然,由于这个是数组操作,就有索引越界的问题(IndexOutOfBoundsException异常)。
对于下面的API其实和AtomicInteger是类似的
void set(int i, int newValue)
void lazySet(int i, int newValue)
int getAndSet(int i, int newValue)
boolean compareAndSet(int i, int expect, int update)
boolean weakCompareAndSet(int i, int expect, int update)
int getAndIncrement(int i)
int getAndDecrement(int i)
int getAndAdd(int i, int delta)
int incrementAndGet(int i)
int decrementAndGet(int i)
int addAndGet(int i, int delta)整体来说,数组的原子操作在理解上还是相对比较容易的,这些API就是有多使用才能体会到它们的好处,而不仅仅是停留在理论阶段。
现在关注字段的原子更新。
字段的原子操作
AtomicIntegerFieldUpdater
相应的API也是非常简单的,但是也是有一些约束的。
- 字段必须是volatile类型的!
- 字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的关系一致。也就是说调用者能够直接操作对象字段,那么就可以反射进行原子操作。但是对于父类的字段,子类是不能直接操作的,尽管子类可以访问父类的字段。
- 只能是实例变量,不能是类变量,也就是说不能加static关键字。
- 只能是可修改变量,不能是final变量,因为final的语义就是不可修改。实际上final的语义和volatile是有冲突的,这两个关键字不能同时存在。
- 对于AtomicIntegerFieldUpdater和AtomicLongFieldUpdater只能修改int/long类型的字段,不能修改其包装类型(Integer/Long)。如果要修改包装类型就需要使用AtomicReferenceFieldUpdater。
在下面的例子中描述了操作的方法。
public class AtomicIntegerFieldUpdaterDemo {
class DemoData{
public volatile int value1 = 1;
volatile int value2 = 2;
protected volatile int value3 = 3;
private volatile int value4 = 4;
}
AtomicIntegerFieldUpdater<DemoData> getUpdater(String fieldName) {
return AtomicIntegerFieldUpdater.newUpdater(DemoData.class, fieldName);
}
void doit() {
DemoData data = new DemoData();
System.out.println("1 ==> "+getUpdater("value1").getAndSet(data, 10));
System.out.println("3 ==> "+getUpdater("value2").incrementAndGet(data));
System.out.println("2 ==> "+getUpdater("value3").decrementAndGet(data));
System.out.println("true ==> "+getUpdater("value4").compareAndSet(data, 4, 5));
}
public static void main(String[] args) {
AtomicIntegerFieldUpdaterDemo demo = new AtomicIntegerFieldUpdaterDemo();
demo.doit();
}
} 在上面的例子中DemoData的字段value3/value4对于AtomicIntegerFieldUpdaterDemo类是不可见的,因此通过反射是不能直接修改其值的。
AtomicMarkableReference类描述的一个<Object,Boolean>的对,可以原子的修改Object或者Boolean的值,这种数据结构在一些缓存或者状态描述中比较有用。这种结构在单个或者同时修改Object/Boolean的时候能够有效的提高吞吐量。
AtomicStampedReference类维护带有整数“标志”的对象引用,可以用原子方式对其进行更新。对比AtomicMarkableReference类的<Object,Boolean>,AtomicStampedReference维护的是一种类似<Object,int>的数据结构,其实就是对对象(引用)的一个并发计数。但是与AtomicInteger不同的是,此数据结构可以携带一个对象引用(Object),并且能够对此对象和计数同时进行原子操作。
在后面的章节中会提到“ABA问题”,而AtomicMarkableReference/AtomicStampedReference在解决“ABA问题”上很有用。
指令重排序和happens-before
在Java Concurrency in Practice中是这样定义线程安全的:
当多个线程访问一个类时,如果不用考虑这些线程在运行时环境下的调度和交替运行,并且不需要额外的同步及在调用方代码不必做其他的协调,这个类的行为仍然是正确的,那么这个类就是线程安全的。
显然只有资源竞争时才会导致线程不安全,因此无状态对象永远是线程安全的。
原子操作的描述是: 多个线程执行一个操作时,其中任何一个线程要么完全执行完此操作,要么没有执行此操作的任何步骤,那么这个操作就是原子的。
指令重排序
Java语言规范规定了JVM线程内部维持顺序化语义,也就是说只要程序的最终结果等同于它在严格的顺序化环境下的结果,那么指令的执行顺序就可能与代码的顺序不一致。这个过程通过叫做指令的重排序。指令重排序存在的意义在于:JVM能够根据处理器的特性(CPU的多级缓存系统、多核处理器等)适当的重新排序机器指令,使机器指令更符合CPU的执行特点,最大限度的发挥机器的性能。
程序执行最简单的模型是按照指令出现的顺序执行,这样就与执行指令的CPU无关,最大限度的保证了指令的可移植性。这个模型的专业术语叫做顺序化一致性模型。但是现代计算机体系和处理器架构都不保证这一点(因为人为的指定并不能总是保证符合CPU处理的特性)。
我们来看最经典的一个案例。
public class ReorderingDemo {
static int x = 0, y = 0, a = 0, b = 0;
public static void main(String[] args) throws Exception {
for (int i = 0; i < 100; i++) {
x=y=a=b=0;
Thread one = new Thread() {
public void run() {
a = 1;
x = b;
}
};
Thread two = new Thread() {
public void run() {
b = 1;
y = a;
}
};
one.start();
two.start();
one.join();
two.join();
System.out.println(x + " " + y);
}
}
}在这个例子中one/two两个线程修改区x,y,a,b四个变量,在执行100次的情况下,可能得到(0 1)或者(1 0)或者(1 1)。
事实上按照JVM的规范以及CPU的特性有很可能得到(0 0)。当然上面的代码大家不一定能得到(0 0),因为run()里面的操作过于简单,可能比启动一个线程花费的时间还少,因此上面的例子难以出现(0,0)。
但是在现代CPU和JVM上确实是存在的。由于run()里面的动作对于结果是无关的,因此里面的指令可能发生指令重排序,即使是按照程序的顺序执行,数据变化刷新到主存也是需要时间的。
假定是按照a=1;x=b;b=1;y=a;执行的,x=0是比较正常的,虽然a=1在y=a之前执行的,但是由于线程one执行a=1完成后还没有来得及将数据1写回主存(这时候数据是在线程one的堆栈里面的),线程two从主存中拿到的数据a可能仍然是0(显然是一个过期数据,但是是有可能的),这样就发生了数据错误。
在两个线程交替执行的情况下数据的结果就不确定了,在机器压力大,多核CPU并发执行的情况下,数据的结果就更加不确定了。
Happens-before法则
Java存储模型有一个happens-before原则,就是如果动作B要看到动作A的执行结果(无论A/B是否在同一个线程里面执行),那么A/B就需要满足happens-before关系。
在介绍happens-before法则之前介绍一个概念:JMM动作(Java Memeory Model Action),Java存储模型动作。一个动作(Action)包括:变量的读写、监视器加锁和释放锁、线程的start()和join()。后面还会提到锁的。
happens-before完整规则:
同一个线程中的每个Action都happens-before于出现在其后的任何一个Action。
对一个监视器的解锁happens-before于每一个后续对同一个监视器的加锁。
对volatile字段的写入操作happens-before于每一个后续的同一个字段的读操作。
Thread.start()的调用会happens-before于启动线程里面的动作。
Thread中的所有动作都happens-before于其他线程检查到此线程结束或者Thread.join()中返回或者Thread.isAlive()==false。
一个线程A调用另一个另一个线程B的interrupt()都happens-before于线程A发现B被A中断(B抛出异常或者A检测到B的isInterrupted()或者interrupted())。
一个对象构造函数的结束happens-before与该对象的finalizer的开始
如果A动作happens-before于B动作,而B动作happens-before与C动作,那么A动作happens-before于C动作。
volatile语义
volatile相当于synchronized的弱实现,也就是说volatile实现了类似synchronized的语义,却又没有锁机制。它确保对volatile字段的更新以可预见的方式告知其他的线程。
volatile包含以下语义:
Java 存储模型不会对valatile指令的操作进行重排序:这个保证对volatile变量的操作时按照指令的出现顺序执行的。
volatile变量不会被缓存在寄存器中(只有拥有线程可见)或者其他对CPU不可见的地方,每次总是从主存中读取volatile变量的结果。也就是说对于volatile变量的修改,其它线程总是可见的,并且不是使用自己线程栈内部的变量。也就是在happens-before法则中,对一个valatile变量的写操作后,其后的任何读操作理解可见此写操作的结果。
尽管volatile变量的特性不错,但是volatile并不能保证线程安全的,也就是说volatile字段的操作不是原子性的,volatile变量只能保证可见性(一个线程修改后其它线程能够理解看到此变化后的结果),要想保证原子性,目前为止只能加锁!
volatile通常在下面的场景:
volatile boolean done = false;
…
while( ! done ){
dosomething();
}应用volatile变量的三个原则:
写入变量不依赖此变量的值,或者只有一个线程修改此变量
变量的状态不需要与其它变量共同参与不变约束
访问变量不需要加锁
原子操作
在JDK 5之前Java语言是靠synchronized关键字保证同步的,这会导致有锁(后面的章节还会谈到锁)。
锁机制存在以下问题:
在多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调度延时,引起性能问题。
一个线程持有锁会导致其它所有需要此锁的线程挂起。
如果一个优先级高的线程等待一个优先级低的线程释放锁会导致优先级倒置,引起性能风险。
volatile是不错的机制,但是volatile不能保证原子性。因此对于同步最终还是要回到锁机制上来。
独占锁是一种悲观锁,synchronized就是一种独占锁,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。而另一个更加有效的锁就是乐观锁。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。
CAS 操作
上面的乐观锁用到的机制就是CAS,Compare and Swap。
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
非阻塞算法 (nonblocking algorithms):
一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。
现代的CPU提供了特殊的指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些代替了锁定。
拿出AtomicInteger来研究在没有锁的情况下是如何做到数据正确性的。
private volatile int value;首先毫无疑问,在没有锁的机制下可能需要借助volatile原语,保证线程间的数据是可见的(共享的)。
这样才获取变量的值的时候才能直接读取。
public final int get() {
return value;
}然后来看看++i是怎么做到的。
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}在这里采用了CAS操作,每次从内存中读取数据然后将此数据和+1后的结果进行CAS操作,如果成功就返回结果,否则重试直到成功为止。
而compareAndSet利用JNI来完成CPU指令的操作。
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}整体的过程就是这样子的,利用CPU的CAS指令,同时借助JNI来完成Java的非阻塞算法。其它原子操作都是利用类似的特性完成的。
而整个J.U.C都是建立在CAS之上的,因此对于synchronized阻塞算法,J.U.C在性能上有了很大的提升。参考资料的文章中介绍了如果利用CAS构建非阻塞计数器、队列等数据结构。
CAS看起来很爽,但是会导致“ABA问题”。
CAS算法实现一个重要前提需要取出内存中某时刻的数据,而在下时刻比较并替换,那么在这个时间差类会导致数据的变化。
比如说一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且two进行了一些操作变成了B,然后two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后one操作成功。尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。如果链表的头在变化了两次后恢复了原值,但是不代表链表就没有变化。因此前面提到的原子操作AtomicStampedReference/AtomicMarkableReference就很有用了。这允许一对变化的元素进行原子操作。
锁机制
尽管synchronized在语法上已经足够简单了,在JDK 5之前只能借助此实现,但是由于是独占锁,性能却不高,因此JDK 5以后就开始借助于JNI来完成更高级的锁实现。
JDK 5中的锁是接口java.util.concurrent.locks.Lock。另外java.util.concurrent.locks.ReadWriteLock提供了一对可供读写并发的锁。根据前面的规则,我们从java.util.concurrent.locks.Lock的API开始。
void lock();获取锁。
如果锁不可用,出于线程调度目的,将禁用当前线程,并且在获得锁之前,该线程将一直处于休眠状态。
void lockInterruptibly() throws InterruptedException;如果当前线程未被中断,则获取锁。
如果锁可用,则获取锁,并立即返回。
如果锁不可用,出于线程调度目的,将禁用当前线程,并且在发生以下两种情况之一以前,该线程将一直处于休眠状态:
- 锁由当前线程获得
- 其他某个线程中断当前线程,并且支持对锁获取的中断
如果当前线程处于以下两种情况时, 则将抛出 InterruptedException,并清除当前线程的已中断状态。:
- 在进入此方法时已经设置了该线程的中断状态
- 在获取锁时被中断,并且支持对锁获取的中断
Condition newCondition();返回绑定到此 Lock 实例的新 Condition 实例。
boolean tryLock();仅在调用时锁为空闲状态才获取该锁。
如果锁可用,则获取锁,并立即返回值 true。如果锁不可用,则此方法将立即返回值 false。
通常对于那些不是必须获取锁的操作可能有用。
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;如果锁在给定的等待时间内空闲,并且当前线程未被中断,则获取锁。
如果锁可用,则此方法将立即返回值 true。如果锁不可用,出于线程调度目的,将禁用当前线程,并且在发生以下三种情况之一前,该线程将一直处于休眠状态:
- 锁由当前线程获得
- 其他某个线程中断当前线程,并且支持对锁获取的中断
- 已超过指定的等待时间
如果获得了锁,则返回值 true。
如果当前线程:
- 在进入此方法时已经设置了该线程的中断状态
- 在获取锁时被中断,并且支持对锁获取的中断,
则将抛出 InterruptedException,并会清除当前线程的已中断状态。
如果超过了指定的等待时间,则将返回值 false。如果 time 小于等于 0,该方法将完全不等待。
void unlock();释放锁。对应于lock()、tryLock()、tryLock(xx)、lockInterruptibly()等操作,如果成功的话应该对应着一个unlock(),这样可以避免死锁或者资源浪费。
public class AtomicIntegerWithLock {
private int value;
private Lock lock = new ReentrantLock();
public AtomicIntegerWithLock() {
super();
}
public AtomicIntegerWithLock(int value) {
this.value = value;
}
public final int get() {
lock.lock();
try {
return value;
} finally {
lock.unlock();
}
}
public final void set(int newValue) {
lock.lock();
try {
value = newValue;
} finally {
lock.unlock();
}
}
public final int getAndSet(int newValue) {
lock.lock();
try {
int ret = value;
value = newValue;
return ret;
} finally {
lock.unlock();
}
}
public final boolean compareAndSet(int expect, int update) {
lock.lock();
try {
if (value == expect) {
value = update;
return true;
}
return false;
} finally {
lock.unlock();
}
}
public final int getAndIncrement() {
lock.lock();
try {
return value++;
} finally {
lock.unlock();
}
}
public final int getAndDecrement() {
lock.lock();
try {
return value--;
} finally {
lock.unlock();
}
}
public final int incrementAndGet() {
lock.lock();
try {
return ++value;
} finally {
lock.unlock();
}
}
public final int decrementAndGet() {
lock.lock();
try {
return --value;
} finally {
lock.unlock();
}
}
public String toString() {
return Integer.toString(get());
}
}类AtomicIntegerWithLock是线程安全的,此结构中大量使用了Lock对象的lock/unlock方法对。
同样可以看到的是对于自增和自减操作使用了++/–。
之所以能够保证线程安全,是因为Lock对象的lock()方法保证了只有一个线程能够只有此锁。
需要说明的是对于任何一个lock()方法,都需要一个unlock()方法与之对于,通常情况下为了保证unlock方法总是能够得到执行,unlock方法被置于finally块中。
另外这里使用了java.util.concurrent.locks.ReentrantLock.ReentrantLock对象,下一个小节中会具体描述此类作为Lock的唯一实现是如何设计和实现的。
尽管synchronized实现Lock的相同语义,并且在语法上比Lock要简单多,但是前者却比后者的开销要大得多。做一个简单的测试。
jdk1.6之后, synchronized已经引入了偏向锁,轻量级锁,性能大大提升. 性能已经不是Synchronized和Lock之间选择的比较了
AQS
在理解J.U.C原理以及锁机制之前,我们来介绍J.U.C框架最核心也是最复杂的一个基础类:java.util.concurrent.locks.AbstractQueuedSynchronizer。
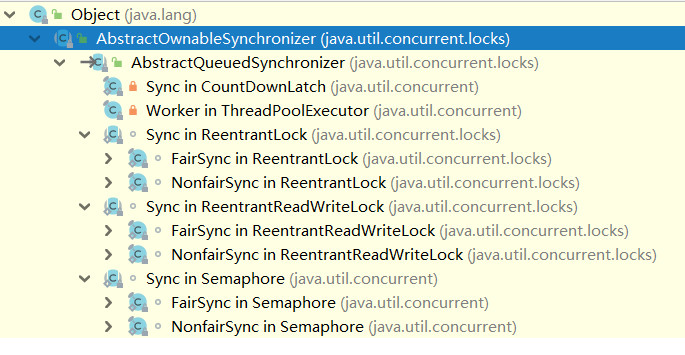
上面的继承体系中,AbstractQueuedSynchronizer是CountDownLatch/FutureTask/ReentrantLock/RenntrantReadWriteLock/Semaphore的基础,因此AbstractQueuedSynchronizer是Lock/Executor实现的前提。
公平锁、不公平锁、Condition、CountDownLatch、Semaphore等放到后面的篇幅中说明。
完整的设计原理可以参考Doug Lea的论文 The java.util.concurrent Synchronizer Framework ,这里做一些简要的分析。
基本的思想是表现为一个同步器,支持下面两个操作:
获取锁:
首先判断当前状态是否允许获取锁,如果是就获取锁,否则就阻塞操作或者获取失败.
也就是说如果是独占锁就可能阻塞,如果是共享锁就可能失败。
另外如果是阻塞线程,那么线程就需要进入阻塞队列。当状态位允许获取锁时就修改状态,并且如果进了队列就从队列中移除。
while(synchronization state does not allow acquire){
enqueue current thread if not already queued;
possibly block current thread;
}
dequeue current thread if it was queued;释放锁:
这个过程就是修改状态位,如果有线程因为状态位阻塞的话就唤醒队列中的一个或者更多线程。
update synchronization state;
if(state may permit a blocked thread to acquire)
unlock one or more queued threads;要支持上面两个操作就必须有下面的条件:
- 原子性操作同步器的状态位
- 阻塞和唤醒线程
- 一个有序的队列
目标明确,要解决的问题也清晰了,那么剩下的就是解决上面三个问题。
状态位的原子操作
这里使用一个32位的整数来描述状态位,前面章节的原子操作的理论知识整好派上用场,在这里依然使用CAS操作来解决这个问题。事实上这里还有一个64位版本的同步器(AbstractQueuedLongSynchronizer),这里暂且不谈。
阻塞和唤醒线程
标准的JAVA API里面是无法挂起(阻塞)一个线程,然后在将来某个时刻再唤醒它的。JDK 1.0的API里面有Thread.suspend和Thread.resume,并且一直延续了下来。但是这些都是过时的API,而且也是不推荐的做法。
在JDK 5.0以后利用JNI在LockSupport类中实现了此特性。
LockSupport.park()
LockSupport.park(Object)
LockSupport.parkNanos(Object, long)
LockSupport.parkNanos(long)
LockSupport.parkUntil(Object, long)
LockSupport.parkUntil(long)
LockSupport.unpark(Thread)上面的API中park()是在当前线程中调用,导致线程阻塞,带参数的Object是挂起的对象,这样监视的时候就能够知道此线程是因为什么资源而阻塞的。
由于park()立即返回,所以通常情况下需要在循环中去检测竞争资源来决定是否进行下一次阻塞。park()返回的原因有三:
- 其他某个线程调用将当前线程作为目标调用 unpark;
- 其他某个线程中断当前线程;
- 该调用不合逻辑地(即毫无理由地)返回。
其实第三条就决定了需要循环检测了,类似于通常写的while(checkCondition()){Thread.sleep(time);}类似的功能。
有序队列
在AQS中采用CHL列表来解决有序的队列的问题。
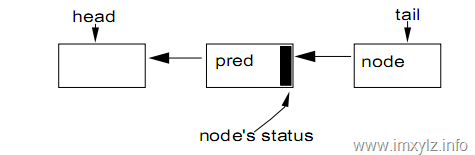
AQS采用的CHL模型采用下面的算法完成FIFO的入队列和出队列过程。
对于入队列(enqueue):采用CAS操作,每次比较尾结点是否一致,然后插入的到尾结点中。
do {
pred = tail;
}while ( !compareAndSet(pred,tail,node) );对于出队列(dequeue):由于每一个节点也缓存了一个状态,决定是否出队列,因此当不满足条件时就需要自旋等待,一旦满足条件就将头结点设置为下一个节点。
while (pred.status != RELEASED) ;
head = node;实际上这里自旋等待也是使用LockSupport.park()来实现的。
AQS里面有三个核心字段:
private volatile int state;
private transient volatile Node head;
private transient volatile Node tail;其中state描述的有多少个线程取得了锁,对于互斥锁来说state<=1。
head/tail加上CAS操作就构成了一个CHL的FIFO队列。
下面是Node节点的属性。
volatile int waitStatus; 节点的等待状态,一个节点可能位于以下几种状态:
ANCELLED = 1: 节点操作因为超时或者对应的线程被interrupt。节点不应该留在此状态,一旦达到此状态将从CHL队列中踢出。
SIGNAL = -1: 节点的继任节点是(或者将要成为)BLOCKED状态(例如通过LockSupport.park()操作),因此一个节点一旦被释放(解锁)或者取消就需要唤醒(LockSupport.unpack())它的继任节点。
CONDITION = -2:表明节点对应的线程因为不满足一个条件(Condition)而被阻塞。
0: 正常状态,新生的非CONDITION节点都是此状态。
非负值标识节点不需要被通知(唤醒)。
volatile Node prev;此节点的前一个节点。节点的waitStatus依赖于前一个节点的状态。
volatile Node next;此节点的后一个节点。后一个节点是否被唤醒(uppark())依赖于当前节点是否被释放。
volatile Thread thread;节点绑定的线程。
Node nextWaiter;下一个等待条件(Condition)的节点,由于Condition是独占模式,因此这里有一个简单的队列来描述Condition上的线程节点。
Lock
public void java.util.concurrent.locks.ReentrantLock.lock()获取锁。
如果该锁没有被另一个线程保持,则获取该锁并立即返回,将锁的保持计数设置为 1。
如果当前线程已经保持该锁,则将保持计数加 1,并且该方法立即返回。
如果该锁被另一个线程保持,则出于线程调度的目的,禁用当前线程,并且在获得锁之前,该线程将一直处于休眠状态,此时锁保持计数被设置为 1。
从上面的文档可以看出ReentrantLock是可重入锁的实现。
而内部是委托java.util.concurrent.locks.ReentrantLock.Sync.lock()实现的。
java.util.concurrent.locks.ReentrantLock.Sync是抽象类,有java.util.concurrent.locks.ReentrantLock.FairSync和java.util.concurrent.locks.ReentrantLock.NonfairSync两个实现,也就是常说的公平锁和不公平锁。
公平锁和非公平锁
如果获取一个锁是按照请求的顺序得到的,那么就是公平锁,否则就是非公平锁。
在没有深入了解内部机制及实现之前,先了解下为什么会存在公平锁和非公平锁。
公平锁保证一个阻塞的线程最终能够获得锁,因为是有序的,所以总是可以按照请求的顺序获得锁。
不公平锁意味着后请求锁的线程可能在其前面排列的休眠线程恢复前拿到锁,这样就有可能提高并发的性能。
这是因为通常情况下挂起的线程重新开始与它真正开始运行,二者之间会产生严重的延时。
因此非公平锁就可以利用这段时间完成操作。
这是非公平锁在某些时候比公平锁性能要好的原因之一。
二者在实现上的区别会在后面介绍,我们先从公平锁(FairSync)开始。
前面说过java.util.concurrent.locks.AbstractQueuedSynchronizer (AQS)是Lock的基础,对于一个FairSync而言,lock()就直接调用AQS的acquire(int arg);
public final void acquire(int arg) 以独占模式获取对象,忽略中断。通过至少调用一次 tryAcquire(int) 来实现此方法,并在成功时返回。否则在成功之前,一直调用 tryAcquire(int) 将线程加入队列,线程可能重复被阻塞或不被阻塞。
在介绍实现之前先要补充上一节的知识,对于一个AQS的实现而言,通常情况下需要实现以下方法来描述如何锁定线程。
- tryAcquire(int) 试图在独占模式下获取对象状态。此方法应该查询是否允许它在独占模式下获取对象状态,如果允许,则获取它。
- tryRelease(int) 试图设置状态来反映独占模式下的一个释放。 此方法总是由正在执行释放的线程调用。释放锁可能失败或者抛出异常,这个在后面会具体分析。
- tryAcquireShared(int) 试图在共享模式下获取对象状态。
- tryReleaseShared(int) 试图设置状态来反映共享模式下的一个释放。
- isHeldExclusively() 如果对于当前(正调用的)线程,同步是以独占方式进行的,则返回 true。
除了tryAcquire(int)外,其它方法会在后面具体介绍。
首先对于ReentrantLock而言,不管是公平锁还是非公平锁,都是独占锁,也就是说同时能够有一个线程持有锁。
因此对于acquire(int arg)而言,arg==1。在AQS中acquire的实现如下:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}这个看起来比较复杂,我们分解以下4个步骤。
- 如果tryAcquire(arg)成功,那就没有问题,已经拿到锁,整个lock()过程就结束了。如果失败进行操作2。
- 创建一个独占节点(Node)并且此节点加入CHL队列末尾。进行操作3。
- 自旋尝试获取锁,失败根据前一个节点来决定是否挂起(park()),直到成功获取到锁。进行操作4。
- 如果当前线程已经中断过,那么就中断当前线程(清除中断位)。
这是一个比较复杂的过程,我们按部就班一个一个分析。
tryAcquire(acquires)
对于公平锁而言,它的实现方式如下:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (isFirst(current) &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}在这段代码中,前面说明对于AQS存在一个state来描述当前有多少线程持有锁。
由于AQS支持共享锁(例如读写锁,后面会继续讲),所以这里state>=0,但是由于ReentrantLock是独占锁,所以这里不妨理解为0<=state,acquires=1。
isFirst(current)是一个很复杂的逻辑,包括踢出无用的节点等复杂过程,这里暂且不提,大体上的意思是说判断AQS是否为空或者当前线程是否在队列头(为了区分公平与非公平锁)。
- 如果当前锁有其它线程持有,c!=0,进行操作2。否则,如果当前线程在AQS队列头部,则尝试将AQS状态state设为acquires(等于1),成功后将AQS独占线程设为当前线程返回true,否则进行2。这里可以看到compareAndSetState就是使用了CAS操作。
- 判断当前线程与AQS的独占线程是否相同,如果相同,那么就将当前状态位加1(这里+1后结果为负数后面会讲,这里暂且不理它),修改状态位,返回true,否则进行3。这里之所以不是将当前状态位设置为1,而是修改为旧值+1呢?这是因为ReentrantLock是可重入锁,同一个线程每持有一次就+1。
- 返回false。
比较非公平锁的tryAcquire实现java.util.concurrent.locks.ReentrantLock.Sync.nonfairTryAcquire(int),公平锁多了一个判断当前节点是否在队列头,这个就保证了是否按照请求锁的顺序来决定获取锁的顺序(同一个线程的多次获取锁除外)。
现在再回头看公平锁和非公平锁的lock()方法。公平锁只有一句acquire(1);而非公平锁的调用如下:
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}很显然,非公平锁在第一次获取锁,或者其它线程释放锁后(可能等待),优先采用compareAndSetState(0,1)然后设置AQS独占线程而持有锁,这样有时候比acquire(1)顺序检查锁持有而要高效。
即使在重入锁上,也就是compareAndSetState(0,1)失败,但是是当前线程持有锁上,非公平锁也没有问题。
addWaiter(mode)
tryAcquire失败就意味着入队列了。此时AQS的队列中节点Node就开始发挥作用了。
一般情况下AQS支持独占锁和共享锁,而独占锁在Node中就意味着条件(Condition)队列为空(上一篇中介绍过相关概念)。
在java.util.concurrent.locks.AbstractQueuedSynchronizer.Node中有两个常量,
//独占节点模式
static final Node EXCLUSIVE = null;
//共享节点模式
static final Node SHARED = new Node(); addWaiter(mode)中的mode就是节点模式,也就是共享锁还是独占锁模式。
前面一再强调ReentrantLock是独占锁模式。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);
return node;
}上面是节点如队列的一部分。当前仅当队列不为空并且将新节点插入尾部成功后直接返回新节点。否则进入enq(Node)进行操作。
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
Node h = new Node(); // Dummy header
h.next = node;
node.prev = h;
if (compareAndSetHead(h)) {
tail = node;
return h;
}
}
else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}enq(Node)去队列操作实现了CHL队列的算法,如果为空就创建头结点,然后同时比较节点尾部是否是改变来决定CAS操作是否成功,当且仅当成功后才将为不节点的下一个节点指向为新节点。可以看到这里仍然是CAS操作。
acquireQueued(node,arg)
自旋请求锁,如果可能的话挂起线程,直到得到锁,返回当前线程是否中断过(如果park()过并且中断过的话有一个interrupted中断位)。
final boolean acquireQueued(final Node node, int arg) {
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} catch (RuntimeException ex) {
cancelAcquire(node);
throw ex;
}
}下面的分析就需要用到上节节点的状态描述了。acquireQueued过程是这样的:
- 如果当前节点是AQS队列的头结点(如果第一个节点是DUMP节点也就是傀儡节点,那么第二个节点实际上就是头结点了),就尝试在此获取锁tryAcquire(arg)。如果成功就将头结点设置为当前节点(不管第一个结点是否是DUMP节点),返回中断位。否则进行2。
- 检测当前节点是否应该park(),如果应该park()就挂起当前线程并且返回当前线程中断位。进行操作1。
一个节点是否该park()是关键,这是由方法java.util.concurrent.locks.AbstractQueuedSynchronizer.shouldParkAfterFailedAcquire(Node, Node)实现的。
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int s = pred.waitStatus;
if (s < 0) return true;
if (s > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else compareAndSetWaitStatus(pred, 0, Node.SIGNAL);
return false;
}- 如果前一个节点的等待状态waitStatus<0,也就是前面的节点还没有获得到锁,那么返回true,表示当前节点(线程)就应该park()了。否则进行2。
- 如果前一个节点的等待状态waitStatus>0,也就是前一个节点被CANCELLED了,那么就将前一个节点去掉,递归此操作直到所有前一个节点的waitStatus<=0,进行4。否则进行3。
- 前一个节点等待状态waitStatus=0,修改前一个节点状态位为SINGAL,表示后面有节点等待你处理,需要根据它的等待状态来决定是否该park()。进行4。
- 返回false,表示线程不应该park()。
selfInterrupt()
private static void selfInterrupt() {
Thread.currentThread().interrupt();
}如果线程曾经中断过(或者阻塞过)(比如手动interrupt()或者超时等等,那么就再中断一次,中断两次的意思就是清除中断位)。




