多线程与高并发(一)
程序, 进程, 线程, 纤程(协程)
程序
程序就是硬盘上保存的可执行的代码
进程
程序开始执行, 硬盘上的代码加载到内存中就叫进程
线程
线程就是进程调度的最小单位
纤程(协程)
用户态的线程
Thread
Thread类的run()方法和start()方法
先看一个简单的例子
private static class T1 extends Thread{
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
TimeUnit.MICROSECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T1");
}
}
}
public static void main(String[] args) {
new T1().run();
for (int i = 0; i < 10; i++) {
try {
TimeUnit.MICROSECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main");
}
}在main()方法中直接new了一个Thread类, 然后调用它的run()方法.
输出:
T1
T1
T1
T1
T1
T1
T1
T1
T1
T1
main
main
main
main
main
main
main
main
main
main可以看到, 先输出’T1’ 再输出’main’
因为, 直接调用run()方法, 执行run()方法的仍然是main线程.
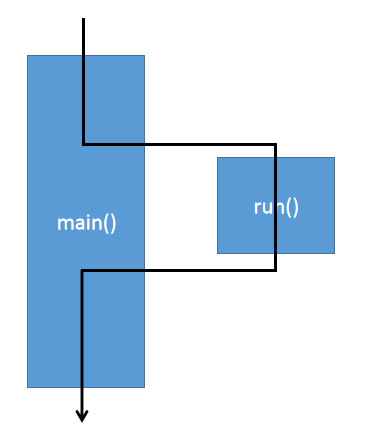
如果调用Thread的start()方法,输出就几乎是交替执行了
private static class T1 extends Thread{
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
TimeUnit.MICROSECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("T1");
}
}
}
public static void main(String[] args) {
// new T1().run();
new T1().start();
for (int i = 0; i < 10; i++) {
try {
TimeUnit.MICROSECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main");
}
}输出
main
T1
main
T1
main
T1
main
T1
main
T1
main
T1
main
T1
main
T1
main
T1
T1
main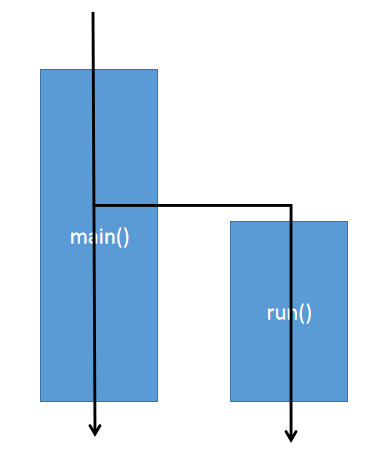
这是run()方法和start()方法的主要区别.
启动线程的几种方式
- 继承Thread类
- 传入Runnable接口的实现类
- 线程池
static class MyThread extends Thread{
@Override
public void run() {
System.out.println("run my Thread");
}
}
static class MyRun implements Runnable{
@Override
public void run() {
System.out.println("run myRUN");
}
}
public static void main(String[] args) {
new MyThread().start();
new Thread(new MyRun()).start();
new Thread(() -> {
System.out.println("run Lambda");
}).start();
// 阿里代码规约中不建议使用这种方式, 这个以后再谈
Executors.newCachedThreadPool().execute(() -> {
System.out.println("run Executor");
});
}基于java8的lambda可以直接匿名的实现一个只有一个方法的接口, 也可以直接在new Thread的时候传入一个lambda表达式.
对线程运行状态的操作
sleep()方法
public static void testSleep(){
new Thread(() -> {
for (int i = 0; i < 100; i++) {
System.out.println("A" + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}sleep()方法的意思是, 当前线程睡眠一段时间,把cpu让渡给其他线程使用.
yield()方法
Thread.yield()方法是要求当前执行的线程先把cpu让出来, 并且当前线程进入等待队列.
在cpu执行的时候, 有可能会拿到原来的线程执行, 也有也能拿到本来就在等待的线程执行.
join()方法
join()方法常用来等待其他线程结束.
public static void testJoin(){
Thread t1 = new Thread(() -> {
for (int i = 0; i < 20; i++) {
System.out.println("A" + i);
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(() -> {
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("B");
});
t1.start();
t2.start();
}在上面这段代码中, 创建了两个线程, t1和t2 .
在t2中调用了 t1.join().
这句代码的意思是, t2线程加入到t1线程中, 等到t1线程执行完了再继续向下执行.
所以,输出是:
A0
A1
A2
A3
A4
A5
A6
A7
A8
A9
A10
A11
A12
A13
A14
A15
A16
A17
A18
A19
B线程的六大状态
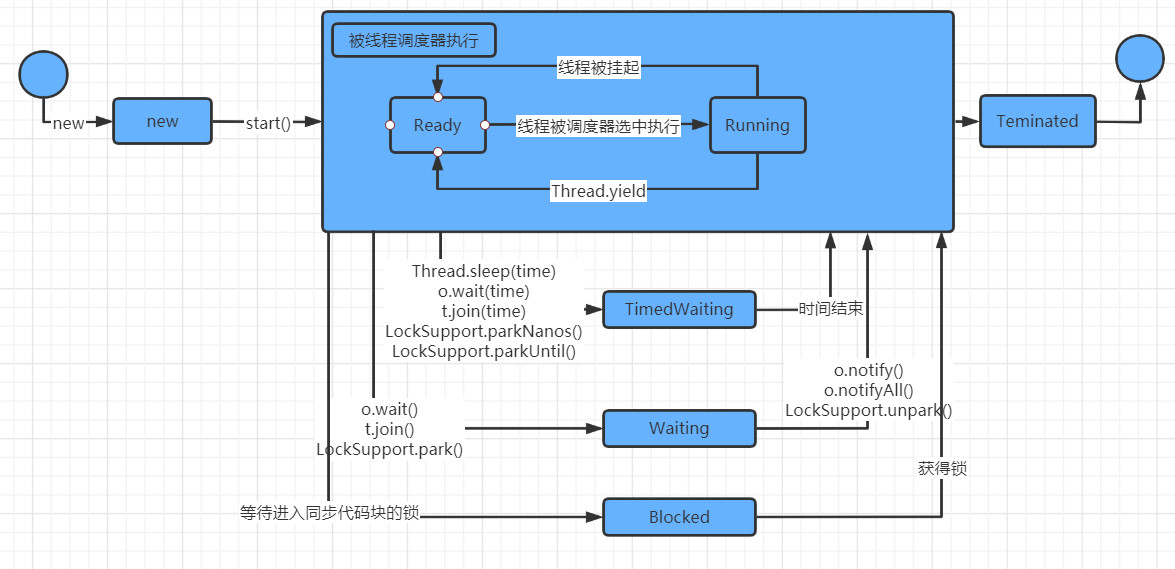
线程大致可以分为六种状态
- new
- Runnable
- Teminated
- TimedWaiting
- Waiting
- Blocked
new
线程被创建出来的时候就是new状态
Runnable
Runnable里又可以分为两个状态, Ready和Running.
Ready就是可以执行,正在等待队列中等待的线程.
Running就是cpu正在执行的线程.
Teminated
线程执行完毕,结束时就是Teminated状态
TimeWaiting
等待一定时间之后会回到Runnable状态
Waiting
当调用了一些方法使线程等待时, 就进入了waiting状态, 需要相应的操作将该状态的线程唤醒.
Blocked
当线程进入同步代码块, 没有获取到锁的时候, 就会是Blocked状态,当获取到锁以后就回到了Runnable状态
可以用Thread中的getState()方法来获取线程当前的状态
static class MyThread extends Thread{
@Override
public void run() {
System.out.println(this.getState());
for (int i = 0; i < 10; i++) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(i);
}
}
}
public static void main(String[] args) {
MyThread t1 = new MyThread();
System.out.println(t1.getState());
t1.start();
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(t1.getState());
}输出:
NEW
RUNNABLE
0
1
2
3
4
5
6
7
8
9
TERMINATEDSynchronized
访问一个共享资源或者一个临界区时, 必须要上锁.
private int count = 10;
private Object o = new Object();
public void m(){
synchronized (o){
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}
}在上面的代码示例中, 在多个线程想要访问count这个资源的时候,必须要获取o的锁.
只有拿到了o,才可以进行下面的–和打印操作.
Synchronized关键字在JVM规范中并没有固定必须如何实现.
在HotSpot中, 是在对象的头中取出2位, makword来实现的.
这两位代表了不同的锁类型.
Synchronized在不同地方的应用
上面我们说了, synchronized可以锁一个对象, 那么也可以锁this对象
private static int count = 10;
public void m(){
synchronized (this){
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}
}当锁对象为this时, 上面这种写法等价于:
private static int count = 10;
public synchronized void m(){
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}当sunchronized用来修饰static的方法时, 锁定的对象是当前类的class对象
private static int count = 10;
public static synchronized void m(){
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}此时等同于直接锁定T.class
private static int count = 10;
public static void m(){
synchronized(Test06.class){
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}
}使用synchronized的例子
public class Test07 implements Runnable{
private int count = 100;
@Override
public void run(){
count --;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}
public static void main(String[] args) {
Test07 t = new Test07();
for (int i = 0; i < 100; i++) {
new Thread(t, "THREAD" + i).start();
}
}
}这段代码显然输出是有问题的, 那只要在run()方法上添加synchronized关键字就可以了.
public class Test07 implements Runnable{
private int count = 100;
@Override
public synchronized void run(){
count --;
System.out.println(Thread.currentThread().getName() + " count = " + count);
}
public static void main(String[] args) {
Test07 t = new Test07();
for (int i = 0; i < 100; i++) {
new Thread(t, "THREAD" + i).start();
}
}
}synchronized是可重入的
假如synchronized是不可重入的, 在同一个方法中,两个synchronized修饰的方法如果相互产生调用, 就会出现死锁的情况.
同样, 如果子类中synchronized修饰的方法调用了super中的方法, 也会产生死锁.
所以synchronized一定是可重入的.
当synchronized中产生抛出异常的时候会自动释放锁
在synchronized修饰的方法中, 如果抛出异常, 会自动释放锁.
如果产生了异常不释放锁的话, 抛到了该方法的调用方, 锁未被释放. 以后所有的线程都没法再获取到这把锁了.
synchronized的底层实现
在JDK早期的时候, synchronized是重量级的. 导致所有的锁都要向操作系统申请锁, 就造成synchronized效率低.
后来进行了 改进, 引入了锁升级
第一个访问的线程时, 在markword中记录这个线程的id (偏向锁) 默认不会产生线程竞争
如果有线程竞争的话, 就升级为自旋锁 (默认情况下自旋10次)
如果10次之后还是没有获得锁, 升级为重量级锁
synchronized升级的过程是不可逆的, 假设一段时间内竞争较激烈, 已经升级为重量级锁了.
之后的一段时间没有太强烈的竞争, 这时轻量级锁的效率会更高.
但是因为锁升级不能回退, 所以不能降级成轻量级锁.
执行时间短, 线程数少的情况下, 用自旋较合适.
执行时间长, 线程数叫多的情况下, 用系统锁更合适.
锁对象发生改变
锁定某对象o, 如果o的属性发生改变, 不影响锁的使用. 但是如果o变成另外一个对象, 则锁定的对象发生改变.
因为synchronized是使用对象头中的markword来判断锁类型,
当前锁的是o对象, 如果使 o = new Object();这种情况下锁对象的markword又重置回没有加锁的状态, 会出现问题.
所以应在锁对象上加上final修饰,以免引用发生改变.
volatile
现象描述
首先看个例子:
public class Test08 {
boolean running = true;
void m(){
System.out.println("m start");
while (running){
}
System.out.println("m end");
}
public static void main(String[] args) {
Test08 t = new Test08();
new Thread(() -> {t.m();}, "t1").start();
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t.running = false;
System.out.println("main end");
}
}启动main线程, 在main中开启了一个线程执行m方法, 如果running没有改变的话, 应该是一个死循环, 永远也不会输出”m end”.
在子线程启动后, 主线程睡眠1毫秒, 确保子线程正在进行死循环.
然后将running设置为false.
按照一般想法, running设置为false, 死循环条件不成立. 结束循环,打印”m end”, 然后结束.
实际上输出了”m start”和”main end”之后 , 程序就一直等在这里.
解决这个问题的方法就是将running加个volatile修饰.
volatile这个词的含义是可变的,易变的.
volatile的作用
volatile有两个作用
- 保证线程可见性
- 禁止指令重排序
保证可见性
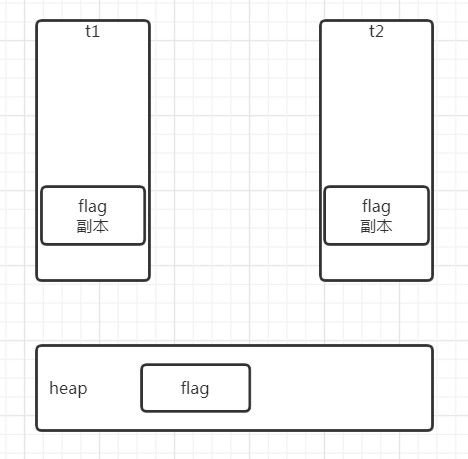
在上图中, t1,t2分别持有在堆中flag变量值的副本.
因为JVM是一个虚拟的计算机, 所以和真实的计算机很像.
每个线程都会从堆中读取出变量的值,维护在自己的工作内存中.
因此t1线程中改变了flag的值, 然后写回堆中, 而并没有通知其他使用到flag的线程.
另一方面, t2中使用flag仍在使用的他自己维护的工作内存中的内容, 什么时候使用flag已经改掉的值也是没法控制的.
这种情况就叫做线程之间不可见.
在硬件上, 多核CPU之间变量的改变是通过MESI协议进行同步的.
而线程是跑在各个CPU上的, 所以volatile也是通过该协议实现的.
禁止指令重排序
指令重排序也是CPU上出现的问题, 现在的CPU为了执行的效率, 会进行指令的乱序执行.
即 会分析找出那些互相没有关联可以并发执行的指令,然后送到几个独立的执行单元进行并发执行.
指令重排序的一个例子是单例模式的双重检查式.
class Singleton{
private Singleton(){}
private static Singleton instance;
public static Singleton getInstance(){
if (instance == null){
synchronized (Singleton.class){
if (instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}上面是一段双重检查的单例模式, instance前面没有加volatile修饰, 运行多次也不会出现什么问题.
但是这个volatile要不要加?
结果是要的.
因为instance = new Singleton(); 的时候, 编译器编译之后, 这条指令会分为三步,
- 申请内存
- 给这个对象的成员变量初始化
- 把这块内存的内容复制给instance
public static void main(String[] args) {
Object o = new Object();
}比如这一小段代码, 就是做了一个new的操作.
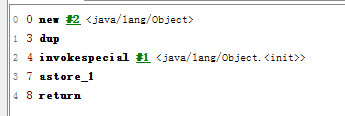
查看他的字节码, 可以发现实际上有四行字节码指令来完成一行new代码的.
如果发生了指令重排序, 2和3换了位置,就会出现这个实例在初始化到一半的时候, 就赋值给instance这个变量了.
如果t1是第一次调用这个方法, getInstance()执行到new一半的时候, 即 执行完 1, 3时, 此时该对象的成员变量还没有初始化, 如果是基础数据类型会有默认值如0, false之类.
这个时候t2也过来调用getInstance()这个方法, 此时进入第一个if判断instance是否为null, 因为3已经执行过了 所以instance不为null, 那么t2执行这个方法就直接返回了.
t2拿到这个实例之后可能会调用里面的一些成员变量, 也就是有可能会拿到未初始化的成员变量的值.
这有可能会出现我们并不想要出现的情况.
volatile不保证原子性
首先看一个例子
public class Test09 {
volatile int count = 0;
void m(){
for (int i = 0; i < 10000; i++) {
count++;
}
}
public static void main(String[] args) {
Test09 t = new Test09();
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < 10; i++) {
threads.add(new Thread(() -> {t.m();}, "thread"+i));
}
threads.forEach((o) -> o.start());
threads.forEach((o) -> {
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(t.count);
}
}在main线程中开启十个线程, 每个线程都对count做10000次自增操作.
最后结果预期应该是 10个线程 * 10000 = 100000.
但是实际输出会小于100000.
为什么呢?
因为自增在字节码指令中不是一个原子操作.
比如有t1,t2两个线程正在同时做操作, 此时count为0.
t1读取count为0, t2读取count为0.
t1做了自增操作此时count为1, t2也做了自增操作此时count为1.
t1将count为1写回堆中, t2感知到了t1的修改, 放弃了工作内存中保存的count值,重新从堆中读取到count为1.
t1写完结束, t2将count为1写回堆中, t2结束.
t1和t2两个线程都做了count++的操作, 按理count应该为2.
但是因为t2在执行时已经做完增加的操作, 感知到t1的提交后放弃了该操作, 导致这时的count值不对.
原子类
AtomicInteger
public class Test10 {
AtomicInteger count = new AtomicInteger(0);
void m(){
for (int i = 0; i < 10000; i++) {
count.incrementAndGet();// count++
}
}
public static void main(String[] args) {
Test10 t = new Test10();
List<Thread> threads = new ArrayList<>();
for (int i = 0; i < 10; i++) {
threads.add(new Thread(t::m, "thread"+i));
}
threads.forEach((o) -> o.start());
threads.forEach((o) -> {
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(t.count);
}
}原子类是Java提供是一系列原子操作, 上面这段代码可以看到, 多线程并发的情况下, 如果是普通的int型, 会需要加锁保证线程安全.
而使用了AtomicInteger就不需要加锁, 他本身就是线程安全的操作.
Atomic类的原理是CAS操作,
// AtomicInteger.java
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
// UnSafe.java
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}可以看到, 在UnSafe类中使用了compareAndSwapInt()方法来保证原子操作.
CAS的含义是 Compare And Set
比较 并且 设置.
cas(V, Expected, NewValue)
if V == Expected
V = NewValue
otherWise try again or fail
如果该变量的值是我期望的值, 我就把他设置成一个新的值. 如果不是期望的值, 说明已经有其他线程更改了这个值. 这个时候就可以再试一遍或者失败操作.
那如果在判断变量值等于期望值的时候, 还没来得及将变量值修改为新的值, 就被其他线程打断了. 这时候怎么办呢?
CAS是CPU原语层面的支持, 确保了原子性不能被打断.
ABA问题
在CAS中会产生一个ABA问题, 比如一个变量i, 预期是1, 新值是2.
t1进行CAS操作的时候, 如果已经将i改为2, 在执行结束将要退出的时候, 再次判断.
此时只能判断i为2, 而不能判断出i是否经历过由2变为3或者其他值, 又再次变成2的过程.
而这不是我们想要的, 我们想要的是t1修改了之后其他所有人都不能再操作成功.
若想解决这个问题, 在CAS的时候加一个版本号, 每次CAS成功都将版本号+1.
Unsafe
Unsafe是直接操作JVM中的内存.
在Java8中是不能直接使用的, 在Java11中做个改变,可以直接获取到了. 而且都改成了弱引用.
- 直接操作内存
- allocateMemory
- putXXX
- freeMemory
- pageSize
- 直接生成类实例
- allocateInstance
- 直接操作类或实例变量
- objectFieldOffset
- getInt
- getObject
- CAS相关操作
- compareAnsSwapObject
- compareAnsSwapInt
- compareAnsSwapLong



