深入理解JVM(一)
Java从编码到执行
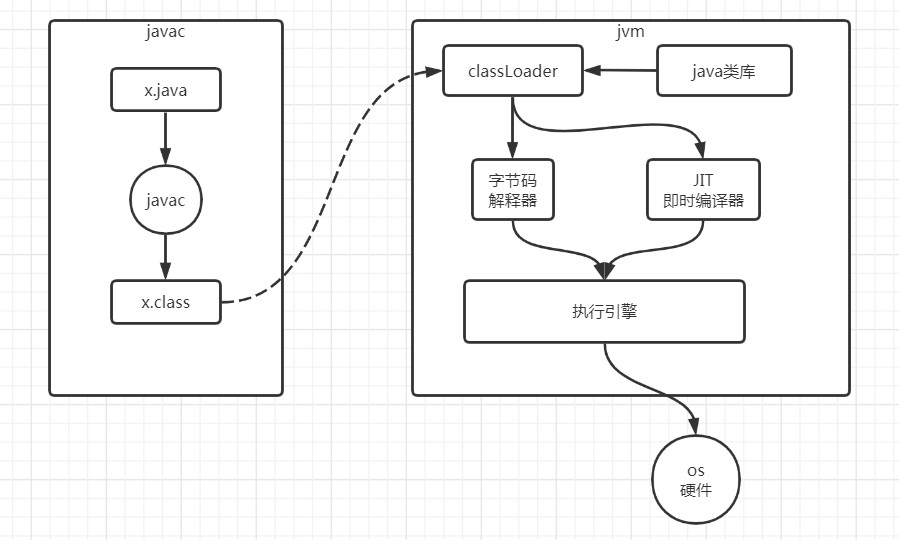
从一个 .java文件到执行, 首先需要经过javac编译成.class文件, 然后使用java执行这个class文件.
在java命令开始后, .class文件会被classLoader加载到内存中, 同时classLoader也会加载一些使用到的java类库.
.class文件进入内存之后会被字节码解释器和JIT即时编译器转换为对应平台的本地机器指令.再通过执行引擎执行.
JVM是跨语言的平台
我们都说Java是跨平台的语言, 其实JVM也是跨语言的平台.
不仅java可以跑在虚拟机中, 有很多其他语言比如 kotlin, scala, jython等也可以直接跑在JVM上.
而JVM又屏蔽了各种操作系统之间的差异.
JVM与class文件格式
JVM与java无关
任何语言, 只要能编译成class, 符合class规范, 就可以运行在jvm上.
JVM是一种规范
JVM是虚拟出来的一台计算机, 有自己的指令集,自己的内存管理.
常见的JVM实现
- Hotspot
- oracle官方, 一般常用的JVM
- java -version
- Jrockit
- BEA, 曾经号称世界上最快的JVM
- 被oracle收购, 合并到hotspot
- J9 - IBM
- Microsoft VM
- TaobaoVM
- hotspot深度定制版
- LiquidVM
- 直接针对硬件
- azul zing
- 最新垃圾回收的业界标杆
- www.azul.com
Class File Format
Class文件内容
public class Test01 {
}就是这么一个简单的类, 在编译完之后生成的class文件

前4个字节 cafebabe 是class文件的开头, 称为magic number 魔数.
5-6个字节 0000 是minor version, 7-8个字节是major version java8的版本是52.
使用Bytecode viewer或者idea安装jclasslib Bytecode viewer可以开启class文件的分析结果页面.
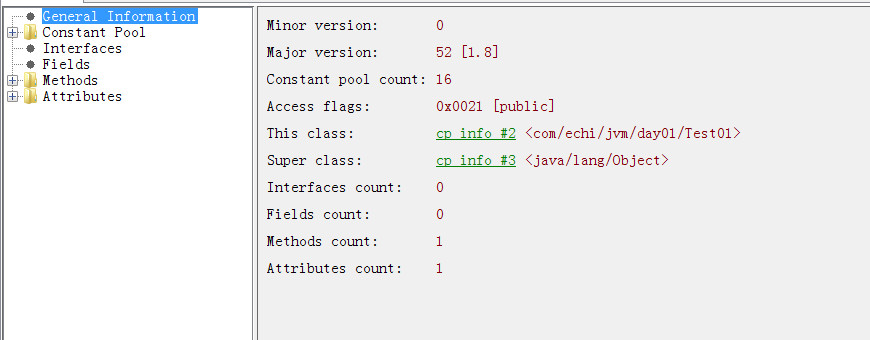
可以看到, 上面的minor version, major version和一些其他信息都显示在上面了.
General Information
Constant pool count: 常量池大小 (常量池的计数是从1开始的, 0预留为了不指向常量池的情况)
Access flags: 用于识别一些类或者接口层次的访问信息
This class: 当前类的信息 (放在常量池2的位置)
Super class: 父类信息 (放在常量池3的位置)
Interfaces count: 实现的接口数
Fields count: 类中的字段数
Methods count: 类中的方法数
Attributes count: 类中的属性数
ConstantPool
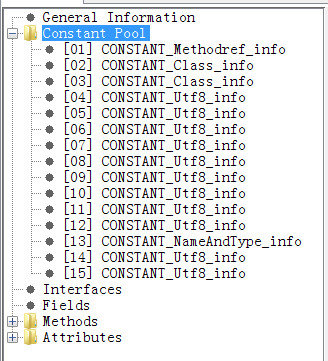
常量池, 常量池中有几种:
- CONSTANT_Utf8_info
- tag:1 – 占用空间一个字节
- length: UTF-8字符串占用的字节数
- bytes: 长度位length的字符串
- CONSTANT_Integer_info
- tag:3
- bytes:4个字节 , Big-Endian(高位在前) 存储的int值
- CONSTANT_Float_info
- tag:4
- 4个字节Big-Endian的float值
- CONSTANT_Long_info
- tag:5
- 8个字节Big-Endian的long值
- CONSTANT_Double_info
- tag:6
- 8个字节Big-Endian的double值
- CONSTANT_Class_info
- tag:7
- index:2字节 指向类的全限定名称的索引
- CONSTANT_String_info
- tag:8
- 2字节, 指向字符串字面量的索引
- CONSTANT_Fieldref_info
- tag:9
- index:2字节 指向声明字段的类或者接口描述符CONSTANT_Class_info的索引项
- index:2字节 指向字段描述符CONSTANT_NameAndType的索引项
- CONSTANT_Methodref_info
- tag:10
- index:2字节 指向声明方法的类或者接口描述符CONSTANT_Class_info的索引项
- index:2字节 指向字段描述符CONSTANT_NameAndType的索引项
- CONSTANT_InterfaceMethodref_info
- tag:11
- index:2字节 指向声明字段的类或者接口描述符CONSTANT_Class_info的索引项
- index:2字节 指向字段描述符CONSTANT_NameAndType的索引项
- CONSTANT_NameAndType_info
- tag:12
- index:2字节 指向该字段或方法名称常量项的索引
- index:2字节 指向该字段或方法描述符常量项的索引
- CONSTANT_MethodHandle_info
- tag:15
- reference_kind:1字节 1-9之间的值, 决定了方法句柄的类型. 方法句柄类型的值表示方法句柄的字节码行为.
- reference_index:2字节 对常量池的有效索引.
- CONSTANT_MethodType_info
- tag:16
- descriptor_index:2字节 指向Utf8_info结构表示的方法描述符
- CONSTANT_InvokeDynamic_info
- tag:18
- bootstrap_method_att_index:2字节 当前Class文件中引导方法表的bootstrap_methods[]数组的有效索引
- name_and_type_index:2字节 指向NameAndTyoe_info表示的方法名和方法描述符
其他还有一些方法, 字段.
类加载和初始化
加载的过程分为三大步, 第二步又分为三小步
- Loading
- Linking
- Verification
- Preparation
- Resolution
- Initializing
Loading
把class装到内存中去
类加载器
JVM中所有的类都是通过类加载器加载到内存的.
当一个class文件被load到内存中后, 实际上有两块内容.
一部分是class文件的二进制在内存中, 另一部分是class对象.
以后我们创建类的对象都是访问class对象, 通过class对象来访问class文件.
public static void main(String[] args) {
// 由引导类加载器加载
System.out.println(String.class.getClassLoader());
// 由扩展类加载器加载
System.out.println(sun.net.spi.nameservice.dns.DNSNameService.class.getClassLoader());
// 由应用类加载器加载
System.out.println(Test01.class.getClassLoader());
// 类加载器也是一个类, 也是由类加载器加载的.
System.out.println(Test01.class.getClassLoader().getClass().getClassLoader());
}可以直接使用 class.getClassLoader() 来获取加载这个类的加载器.
类加载器是分为不同的层次, 不同的类加载器加载不同的class.
最顶层叫Bootstrap, 引导类加载器, 负责加载jdk中最核心的类, 比如 lib/rt.jar charset.jar, 是用C++实现的.
再往下是Extension, 扩展类加载器, 负责加载扩展jar包, jre/lib/ext/下的内容. 或者由 -Djava.ext.dirs指定的.
再下面是App, 应用类加载器, 负责加载classpath中的内容.
一般情况下就是上面这三种类加载器.
还可以有自定义类加载器, 可以自己是实现类加载器.
类加载过程
一个class要被load到内存的时候, 如果是由自定义类加载器加载的话, 自定义加载器先查一下是否已经加载了进来. 如果已经加载了这个类就不再加载.
如果在自己的缓存中没有找到, 并不会直接将类加载到内存, 而是向他的父加载器发出请求, 查询这个类有没有加载, 如果还是没有, 继续向上.
如果一直到Bootstrap都没找到, 就确认是没有加载进内存, 开始实际加载.
Bootstrap在他的加载路径上找不到这个类, 由他的子加载器加载, 扩展类加载器也找不到, 继续向下加载.
直到加载请求传到相应的类加载器, 这个class文件才会被加载到内存.
如果一直到最后都没有加载到这个class, 就会抛出 ClassNotFoundException.
这就是双亲委派机制
这样做的目的是为了安全考虑.
如果我们自己写了一个 java.lang.String类, 并且成功的被加载进去了. 那我们有可能在这个类中做一些危险操作.
因此拿到一个class的时候先向上问问这个class是否已经被加载过了.
父加载器不是类加载器的加载器
public static void main(String[] args) {
System.out.println(Test02.class.getClassLoader());
System.out.println(Test02.class.getClassLoader().getClass().getClassLoader());
System.out.println(Test02.class.getClassLoader().getParent());
System.out.println(Test02.class.getClassLoader().getParent().getParent());
}输出:
sun.misc.Launcher$AppClassLoader@18b4aac2
null
sun.misc.Launcher$ExtClassLoader@76ed5528
null我们自己写的类是由AppClassLoader加载的, AppClassLoader的父加载器是ExtClassLoader.
而AppClassLoader是由Bootstrap加载的.
Launcher
在刚刚的打印中, AppClassLoader和ExtClassLoader都是sun.misc.Launcher内的一个内部类.
// Bootstrap
private static String bootClassPath = System.getProperty("sun.boot.class.path");
// ext
String var0 = System.getProperty("java.ext.dirs");
//App
final String var1 = System.getProperty("java.class.path");
可以打印出这些来看看到底哪个加载器加载了哪些jar包
public static void main(String[] args) {
String pathBoot = System.getProperty("sun.boot.class.path");
System.out.println(pathBoot);
String pathExt = System.getProperty("java.ext.dirs");
System.out.println(pathExt);
String pathApp = System.getProperty("java.class.path");
System.out.println(pathApp);
}自定义类加载器
// ClassLoader.java
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
// 加锁, 以防加载一半又加载一遍
synchronized (getClassLoadingLock(name)) {
// 先查看是否已经加载进来了
Class<?> c = findLoadedClass(name);
if (c == null) {
// 如果没有被加载进来, 开始加载
long t0 = System.nanoTime();
try {
// 调用parent加载
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
// 经过上面父加载器去加载之后, 查询是否已经被加载
if (c == null) {
// 如果还没被加载, 说明父加载器没找到
long t1 = System.nanoTime();
// 调用findClass方法
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
// ClassLoader.java
protected Class<?> findClass(String name) throws ClassNotFoundException {
// ClassLoader中直接抛出一个异常, 留给子类重写
throw new ClassNotFoundException(name);
}因此如果自定义类加载器, 继承ClassLoader, 并且重写findClass方法, 在这个方法中, 读取class文件, 并调用defindClass方法转成class对象.
lazyloading
java的懒加载, 严格讲应该叫 lazyInitializing
JVM规范并没有规定何时加载
但是严格规定了什么时候必须初始化
- new getstatic putstatic invokestatic指令, 访问final变量除外
- java.lang.reflect对类进行反射调用时
- 初始化子类的时候, 父类首先初始化
- 虚拟机启动时,被执行的主类必须初始化
- 动态语言支持java.lang.inoke.MethodHandle解析的结果为REF_getstatic REF_putstatic REF_invokestatic的方法句柄时, 该类必须初始化
编译器
默认是混合模式
解释器
- bytecode intepreter
JIT
- Just In-Time compiler
混合模式
- 混合使用解释器+热点代码编译
- 起始阶段采用解释执行
- 热点代码检测
- 多次被调用的方法 (方法计数器: 检测方法执行频率)
- 多次被调用的循环 (循环计数器: 检测循环执行频率)
- 进行编译
- -Xmixed 默认为混合模式 开始解释执行, 启动速度较快, 对热点代码实行检测和编译
- -Xint 使用编译模式, 启动很快,执行稍慢
- -XComp 使用纯编译模式, 执行很快, 启动很慢
打破双亲委派机制
因为双亲委派机制是在ClassLoader中的loadClass方法中已经完成了的, 所以要想打破这个机制可以重写loadClass方法.
什么时候发生过打破双亲委派机制
- JDK1.2之前, 自定义ClassLoader都必须重写loadClass
- ThreadContextClassLoader可以实现基础类调用实现类代码, 通过thread.setContextClassLoader指定
- 热启动, 热部署
- osgi tomcat都有自己的模块指定classloader(可以加载统一类库的不同版本)
Linking
Verification
验证文件是否符合JVM规定
Preparation
把class文件的静态变量赋默认值
Resolution
在ClassLoader的loadClass中, 有一个布尔值, 这个代表是否进行解析
这个节点就是将类, 方法, 属性等符号引用解析为直接引用
常量池汇总的各种符号引用解析为指针, 偏移量等内存地址的直接饮用
Initializing
调用类初始化代码
解析阶段先看一道题:
public class Test05 {
public static void main(String[] args) {
System.out.println(T.count);
}
}
class T {
public static int count = 2;
public static T t = new T();
private T(){
count ++;
}
}输出是什么.
通过运行得知, 输出为3.
如果将T类中的两个static调换一下位置
public class Test05 {
public static void main(String[] args) {
System.out.println(T.count);
}
}
class T {
public static T t = new T();
public static int count = 2;
private T(){
count ++;
}
}输出就变成了2.
为什么呢?
根据我们之前说的类加载过程, 在Linking的Preparation阶段,
public static int count = 2;
public static T t = new T();会给count和t赋默认值, int的默认值是0, t的默认值是null
再到Initializing阶段, 会给静态变量赋初值, count的值赋为2, t的值调构造方法, 对count++. 所以count为3.
如果两句反过来,
在Preparation阶段, t的null, count是0
再到Initializing阶段, 先对t赋值, 调用构造方法, count++ 此时count为1.
再对count赋初值, count为2.
关于指令重排
public class Test06 {
public static void main(String[] args) {
Test06 t = new Test06();
}
}就这么简单的一个例子
我们去查看他的二进制文件,查看他在main方法处做了什么
0 new #2 <com/echi/jvm/day01/Test06>
3 dup
4 invokespecial #3 <com/echi/jvm/day01/Test06.<init>>
7 astore_1
8 return首先在0处申请了内存
4处调用构造方法, 7是把调用构造方法 完成初始化的这块内存赋值给 t.
在4和7处, 有可能会发生指令重排. 如果7先发生, 就是先把内存地址放到t中了, 其他线程可能就会获取出问题.
JMM
硬件层的并发优化基础知识
存储区的层次结构
- L0: 寄存器
- L1:高速缓存
- L2:高速缓存
- L3:高速缓存
- L4:主存
- L5:磁盘
- L6:远程文件存储
寄存器是最快的, 往下依次速度慢下来.
cache line
缓存行对齐 伪共享
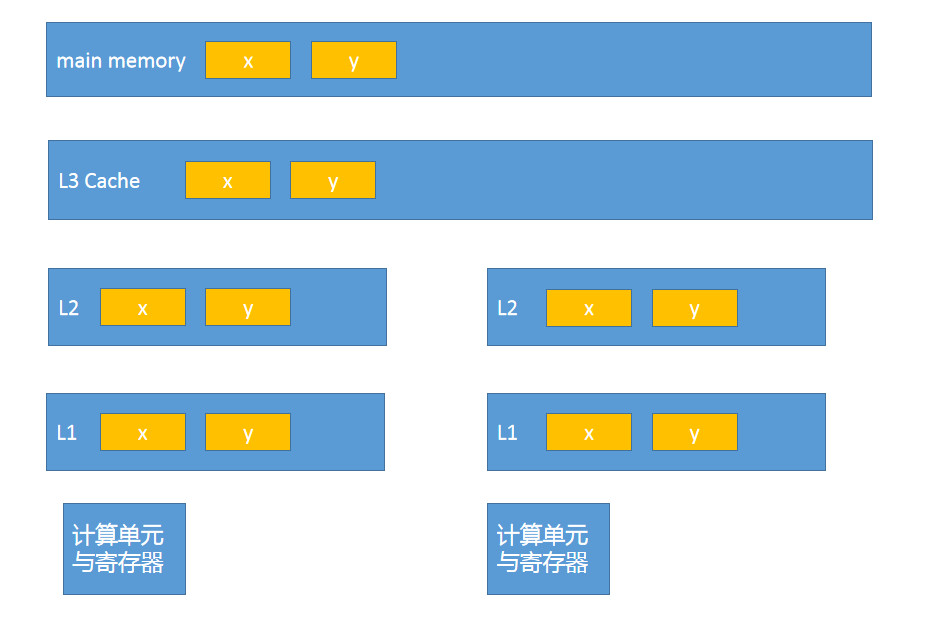
L1和L2都是在CPU的每个核内的, 也就是说, 如果x在第一个计算单元中被改成1 , 在第二个计算单元中被改成2, 这种不一致会如何处理.
总线锁
当操作一个数据的时候, 可以通过对总线加锁的方式防止同时访问.
这种方式效率太低, 如果一个CPU访问x, 把总线上锁之后, 另一个CPU访问y, 也要进行等待.
一致性协议
一般都会说MESI协议, 这是IntelCPU会用的协议, 其他品牌的CPU用的是其他一致性协议.
MESI其实是四种状态 Modified, Exclusive, Shared, Invalid.
- Modified 在当前CPU修改过
- Exclusive 独占, 只有一个CPU在用
- Shared 多个CPU同时在用
- Invalid 如果这个值被其他CPU修改过.
通过该协议对多个CPU之间的缓存保持一致性
比如如果发现自己用的值已经是Invalid状态, 就再去内存读一次.
MESI叫做缓存锁, 原来的总线锁依然存在.
有些无法被缓存的数据, 或者跨越多个缓存行的数据, 依然必须使用总线锁
所以现代CPU数据一致性的实现是由缓存锁+总线锁共同实现的.
缓存行
对于一个数据, 如果想要读取他, 不会单纯的只读取这一个数据, 而是会读取他所在的这一个缓存行.
这个缓存行多数是64字节大小.
现在有一个场景, 两颗CPU, CPU1使用x, CPU2使用y, x和y放在同一个缓存行上.
那么, 当CPU1修改x之后会将整个缓存行修改回去, 而CPU2读取到的x和y都会变成Invalid.
但是CPU2本身不需要收到x的失效信息, CPU1也不会对y进行更改.
这种被叫做伪共享.
位于同一缓存行的两个不同数据. 被两个不同CPU锁定, 产生互相影响的伪共享问题.
缓存行对齐
前面提过这个, 使用几个额外的变量将缓存行补齐, 保证共享的变量不在同一个缓存行上.
乱序问题
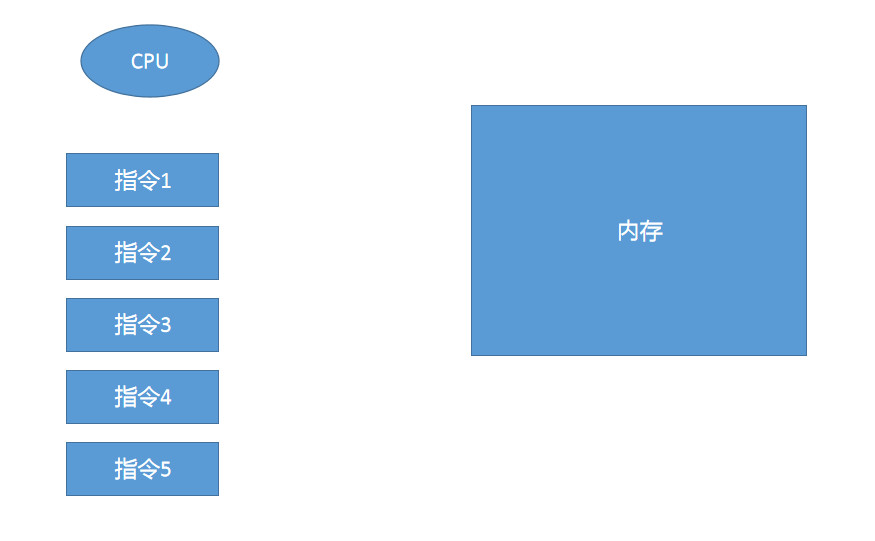
CPU在执行的时候, 如果发现指令1要去内存中读数据.
因为CPU的速度是相当快的, 比内存快100倍.
所以CPU回去分析下面几条指令, 是否有指令不依赖于指令1的.
合并写
CPU在L1高速缓存之前 还有一个WCBuffer, Writing Comblining 合并写.
合并写的容量非常小, 只有4个字节.
当CPU写入L1的时候, 使用WCBuffer写入L2.
证明乱序
public class Test06 {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for (;;){
i++;
x = 0;y = 0;
a = 0;b = 0;
Thread one = new Thread(new Runnable() {
@Override
public void run() {
a = 1;
x = b;
}
});
Thread two = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
y = a;
}
});
one.start();two.start();
one.join();two.join();
String result = "第" + i + "次 ( " + x + ", " + y + ")";
if (x == 0 && y == 0){
System.err.println(result);
break;
}
}
}
}简单分析一下, 两个线程同时开始.
a,b分别赋值, 再把值赋值给x和y.
如果t1先执行, a=1, 此时有两种情况, t2插入进来, b=1先执行. 此时结果为 (1,1)
如果t1没有被打断, 此时x=0,结果为 (0, 1).
如果t2先执行, b=1, 此时也是两种情况, 结果分别为 (1,1)和(1,0).
但是有没有可能会出现 (0,0)呢.
如果是顺序执行, 确实不可能出现 (0,0), 因为x,y想要完成赋值必须要经过a=1或者b=1 或者a,b都等于1.
第209511次 ( 0, 0)但是结果显示, 在数次循环之后, 确实打印出了 (0,0)这种情况.
因此证明了CPU的乱序执行是存在的.
如何解决乱序问题
我们之前提到volatile可以禁止指令重排序.
CPU层面
在CPU层面使用的是内存屏障来防止指令重排序.
内存屏障
拿IntelCPU来说,有三条指令.
sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成
lfence:在lfence指令前的读操作必须在lfence指令后的读操作前完成.
mfence:在mfence指令前的读写操作必须在mfence指令后的读写操作前完成.
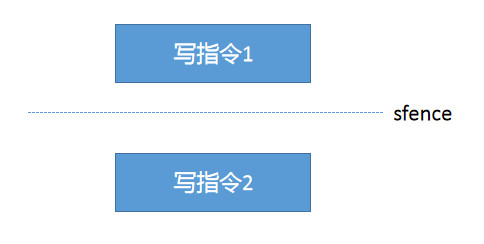
如上图, 在两条写指令中间加入一道sfence, 保证写指令1执行完之后写指令2才能执行.
原子指令
如x86上的”lock …”指令是一个Full Barrier, 执行时会锁住内存子系统来确保执行顺序, 甚至跨多个CPU.
Sofeware Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序.
JVM级别如何规范
LoadLoad屏障:
对于这样的语句 Load1; LoadLoad; Load2,
在Load2及后续读取操作要读取的数据被访问前, 保证Load1要读取的数据被读取完毕.
StoreStore屏障:
对于这样的语句 Store1; StoreStore; Store2.
在Store及后续写入操作执行前, 保证Store1的写入操作对其他处理器可见.
LoadStore屏障:
对于这样的语句 Load1; LoadStore; Store2
在Store2及后续写入操作被刷出前, 保证Load1要读取的数据被读取完毕.
StoreLoad屏障:
对这样的语句 Store1; StoreLoad; Load2
在Load2及后续所有读取操作执行前, 保证Store1的写入对所有处理器可见.
volatile的实现细节
字节码层面
public class Test07 { int i; volatile int j; }对这个类编译后查看他的class文件,
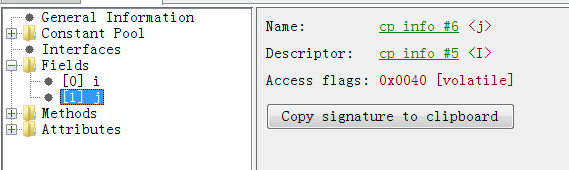
volatile在字节码层面时, Access flags变为0x0040 , 标记为volatile
JVM层面
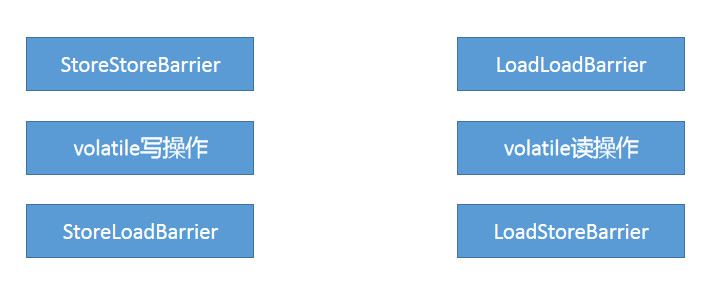
在JVM层面, 对于所有的volatile
在写操作前面加上 StoreStoreBarrier, 在写操作后面加上 StoreLoadBarrier.
在读操作前面加上 LoadLoadBarrier, 在读操作后面加上 LoadStoreBarrier.
OS和硬件层面
windows是使用lock指令实现的.
Synchronized的实现细节
字节码层面
public class Test08 { synchronized void m(){ } void n(){ synchronized (this){} } }对这个类编译后查看他的class文件,
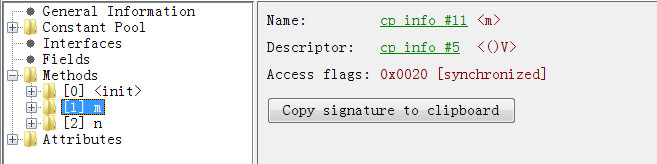
synchronized修饰的方法在字节码层面时, Access flags变为0x0020 , 标记为synchronized
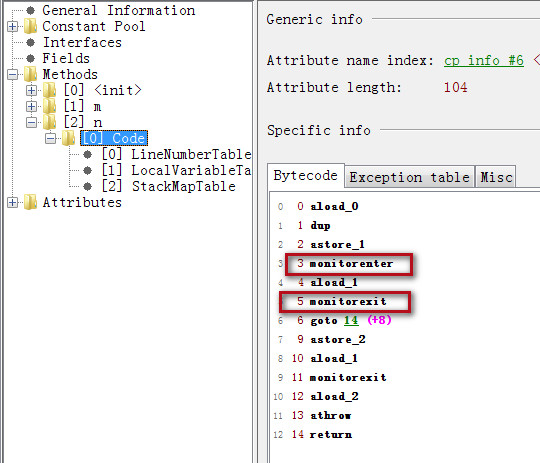
同步代码块会使用monitorenter和moniterexit.
而下面还有一个monitorexit, 是当产生异常的时候, 会自动退出.
JVM层面
C C++调用了操作系统提供的同步机制
OS和硬件层面
x86: lock comxchg xxxxx
Java8大原子操作(虚拟机规范)
(已弃用)
最新的JSR-133已经放弃这种描述, 但是JMM没有变化
- lock: 主内存, 标识变量为线程独占
- unlock: 主内存, 解锁线程独占变量
- read: 主内存, 读取内容到工作内存
- load: 工作内存, read后的值放入线程本地变量副本
- use: 工作内存, 传值给执行引擎
- assign: 工作内存, 执行引擎结果赋值给线程本地变量
- store: 工作内存, 存值到主内存给write备用
- write: 主内存, 写变量值
happens-before原则
JVM规定重排序必须遵守的规则
- 程序次序规则: 同一个线程内, 按照代码出现的顺序, 前面的代码先行与后面的代码, 准确的说是控制流顺序, 因为要考虑到分支和循环结构.
- 管程锁定规则: 一个unlock操作先行发生于后面(时间上)对同一个锁的lock操作.
- volatile变量规则: 对一个volatile变量的写操作先行发生于后面(时间上)对这个变量的读写操作.
- 线程启动规则: Thread的start()方法先行发生于这个线程的每一个操作.
- 线程终止规则: 线程的所有操作都先行与此线程的终止检测. 可以通过Thread.join()方法结束, Thread.isAlive()的返回值等手段检测线程的终止.
- 线程中断规则: 对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断时间的发生, 可以通过Thread.interrupt()方法检测线程是否中断.
- 对象终结规则: 一个对象的初始化完成先行于发生它的finalize()方法的开始.
- 传递性: 如果操作A先行于操作B, 操作B先行于操作C, 那么操作A先行于操作C.
as if serial 不管如何重排序, 单线程执行结果不会改变.
对象的内存布局
对象的创建过程
- class loading
- class linking(verification, preparation, resolution)
- class initializing
- 申请对象内存
- 成员变量赋默认值
- 调用构造方法
- 成员变量顺序赋初始值
- 执行构造方法语句
如果class还没load到内存, 需要先做前面提过的将class加载到内存.
在class加载到内存之后, 需要先申请内存, 然后将成员变量赋默认值 int是0,boolean是false.
然后调用构造方法, 这个构造方法讲的是字节码中的
对象在内存中的存储布局
查看JVM启动参数
java -XX:+PrintCommandLineFlags -version
-XX:InitialHeapSize=132847360 -XX:MaxHeapSize=2125557760 -XX:+PrintCommandLineFl
ags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesInd
ividualAllocation -XX:+UseParallelGC对象大小
普通对象
对象头: markword 8
ClassPointer指针: -XX:+UseCompressedClassPointers 为4字节, 不开启为8字节 开启内存压缩
实例数据
引用类型: -XX:UseCompressedOops 为4字节, 不开启为8字节 开启内存压缩
Oops Ordinary Object Pointers
Padding对齐, 8的倍数
数组对象
- 对象头: markword 8
- 数组长度: 4字节
- 数组数据
- 对齐
public class Test04 {
// markword 8
// class pointer 4
int age; // 4
String name; // 4
int sex; // 4
byte b1; // 1
byte b2; // 1
Object object; // 4
byte b3; // 1
// padding 1
}上面这个对象的大小就是 8+4+4+4+1+1+4+1+1 = 24字节.
HotSpot开启内存压缩的规则(64位)
- 4G以下, 直接砍掉高32位
- 4G - 32G, 默认开启内存压缩 ClassPointers Oops
- 32G, 压缩无效, 使用64位
内存并不是越大越好
对象头具体包括什么
markword结构
32 bits:
--------
hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
size:32 ------------------------------------------>| (CMS free block)
PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
64 bits:
--------
unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
size:64 ----------------------------------------------------->| (CMS free block)
unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
[ptr | 00] locked ptr points to real header on stack
[header | 0 | 01] unlocked regular object header
[ptr | 10] monitor inflated lock (header is wapped out)
[ptr | 11] marked used by markSweep to mark an object
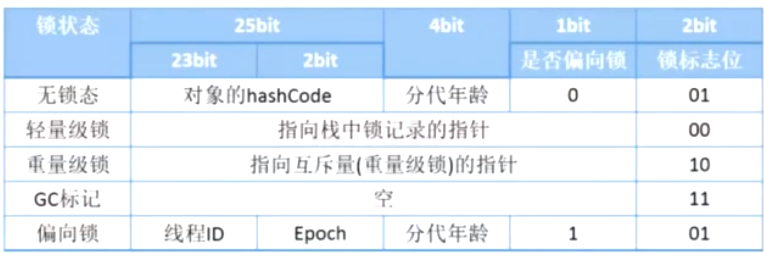
markwrod在对象不同的状态表示的意义也是不同的.
当对象处于无锁态的时候, 使用后3位表示锁状态, 前25位表示hashCode, 如果没有重写过hashCode, 会根据对象的内存地址算出一个.或者调用System.identityHashCode时, 会产生hashCode.
在对象不同的状态时, 最后2位锁标志位是不一样的, GC时也会用到锁.
因为分代年龄只有4位, 因此GC年龄默认是15 且最大是15.
对象定位
句柄池
句柄池就是 当 T t = new T(); 对象new出来之后, t指向两个指针, 一部分指向实例对象的内存, 另一部分指向T.class.
直接指针
直接指针是指, 当对象new出来之后, 指向实例对象, 实例对象指向T.class.
HotSpot使用的就是直接指针,
Runtime Data Area
PC 程序技术器
program counter
存放指令
虚拟机的运行, 类似于这样的循环:
while( not end ){
取PC中的位置, 找到对应位置的指令;
执行该指令;
PC++;
}
Stack 栈
每个线程都独有一个站, 和线程一起创建.
栈中存储的是栈帧.
Heap 堆
堆在线程中共享
Method Area 方法区
方法区在线程中共享.
存储的是class.
在Java8之前, 方法区的实现叫Perm Space永久区, 字符串常量位于Perm Space, FGC不会清理. 大小启动时指定.
在Java8之后, 方法区的实现叫Meta Space元空间, 字符串常量位于堆, FGC会清理. 大小不指定的话最大就是物理内存.
Run-Time Constant Pool
运行时常量池是在每个class或者interface文件中的常量池.
Native Method Stacks
当调用到本地方法的时候, 会用到本地方法栈, 和java的栈类似.
每个线程有自己的程序计数器, 栈和本地方法栈. 所有线程都共享一个堆和方法区.
Frame 栈帧
前面说过, 栈中存储的是一个个的栈帧, 而栈帧中存储的有四部分内容.
局部变量
操作数栈
动态链接
动态链接指的是运行时常量池中对应的记录. 如果还没解析, 就进行动态解析, 然后拿来使用.
返回地址
返回值地址就是方法结束之后, 应该回到哪个地方.
public class Test09 {
public static void main(String[] args) {
int i = 0;
i = i++;
// i = ++i;
System.out.println(i);
}
}先看一道题, 这个输出是多少.
输出是0.
但是为什么会这样, 可以很清楚的看到已经做了i++操作.
我们去看他的二进制文件,
// main 方法编译后的
0 iconst_0
1 istore_1
2 iload_1
3 iinc 1 by 1
6 istore_1
7 getstatic #2 <java/lang/System.out>
10 iload_1
11 invokevirtual #3 <java/io/PrintStream.println>
14 return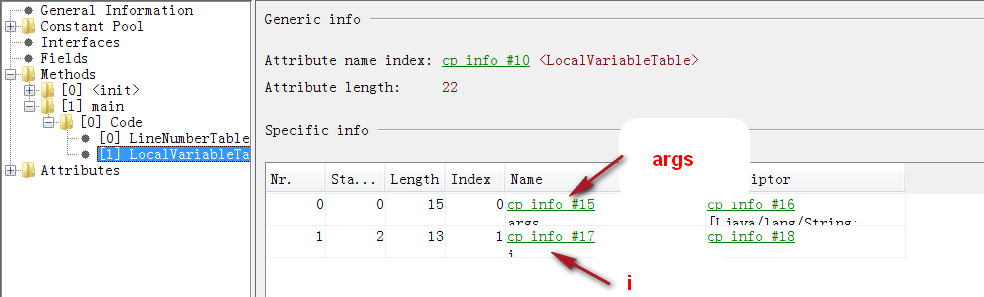
局部变量表中0代表String[] args, 1代表int i;
0 iconst_0 // 将0压入操作数栈
1 istore_1 // 将操作数栈栈顶出栈, 放到局部变量表1的位置 即i的位置
2 iload_1 // 将局部变量表1位置的值load到操作数栈
3 iinc 1 by 1 // 将局部变量表1位置的值加1
6 istore_1 // 将操作数栈的栈顶出栈, 放到局部变量表1的位置
7 getstatic #2 <java/lang/System.out>
10 iload_1
11 invokevirtual #3 <java/io/PrintStream.println>
14 return从3和6我们可以看出, i++是直接在局部变量表中做的自增, 而 i=i++ 做的是先将i的值挪到操作数栈, 在i自增之后, 又将操作数栈中没有自增的值放了回来, 这样就导致了i++的结果丢失.
那么如果++i呢?
public class Test09 {
public static void main(String[] args) {
int i = 8;
// i = i++;
i = ++i;
System.out.println(i);
}
}输出结果是9.
0 bipush 8
2 istore_1
3 iinc 1 by 1
6 iload_1
7 istore_1
8 getstatic #2 <java/lang/System.out>
11 iload_1
12 invokevirtual #3 <java/io/PrintStream.println>
15 return
可以看到 在++i中, iinc 1 by 1这次放到了istroe_1前面, 因此这次的操作就是先自增, 再放到操作数栈, 然后将操作数栈中的数放回局部变量表.
字节码指令
invokexxxx
- invokeStatic 调用静态方法
- invokeVirtual 自带多态的调用
- invokeInterface 通过interface调用的.
- invokeSpecial 可以直接定位的, 不需要多态的 (private方法, 构造方法)
- invokeDynamic 动态的class lambda表达式, 或者反射或者其他动态语言




